Overview
Digital twin models and connectors can be deployed on premises on both Windows and Linux systems using the ScaleOut Digital Twins™ user interface (UI) or by using APIs called from client programs. In both cases, ScaleOut StreamServer® DT’s in-memory data grid provides the execution platform and needs to be installed and configured.
Using the UI
In addition to ScaleOut StreamServer DT, the UI requires two components for use on-premises:
the management server, which is described in the topic Deploying the ScaleOut Digital Twins UI and
the host agent, which is described in the topics Deploying the Host Agent on Windows and Deploying the Host Agent on Linux
The management server is installed on one on-premises computer that hosts the UI. Once configured, the UI can be accessed on this system or from other networked computers. The host agent is installed on all servers running ScaleOut StreamServer DT’s in-memory data grid. For small evaluation projects, the management server and ScaleOut StreamServer DT can be installed on the same system. Production deployments should install ScaleOut StreamServer DT on a separate and dedicated set of servers or VMs.
Note
The UI’s components makes use of Docker containers and requires the installation of Docker on the on-premises computer hosting the UI.
Using APIs
Client applications can use APIs directly to deploy digital twin models to ScaleOut StreamServer DT’s in-memory data grid for execution. These APIs are described in the topic Deploying Models with APIs.
The workflow for building and deploying digital twin models and connectors using APIs instead of the UI is illustrated in the following diagram:
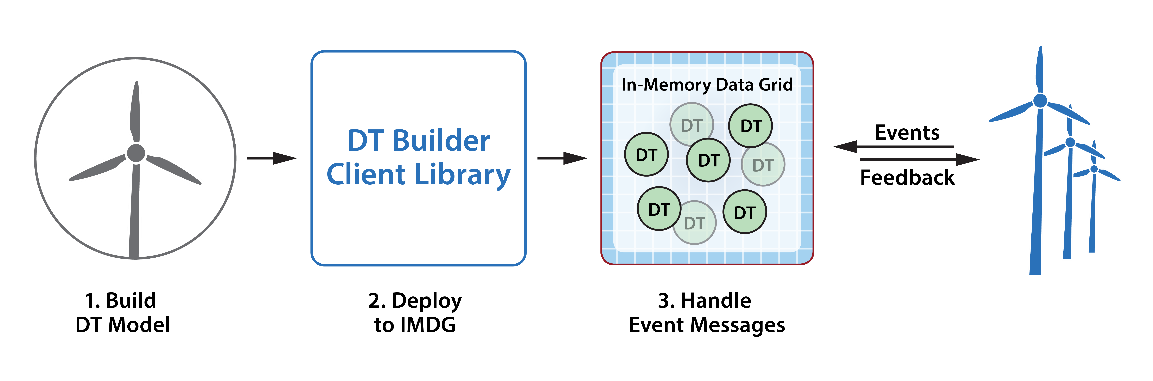
When implementing streaming analytics, client applications also can send messages to real-time digital twin instances, thereby playing the role of data sources. For example, a Java application can deploy the heart-rate tracking sample application described in the shown in the ScaleOut Digital Twin Builder Overview section by creating an execution environment which is deployed to all servers in the grid:
ExecutionEnvironment environment = new ExecutionEnvironmentBuilder()
.addDependencyJar("HeartRateSample.jar")
.addDigitalTwin("HeartRateTracker", new HeartRateMessageProcessor(),
HeartRateTracker.class, HeartRate.class)
.build();
A Java client program can then send a message to instance “tracker_1717” as follows:
byte[] msg = new HeartRate(130, System.currentTimeMillis()).toJson();
SendingResult result = AppEndpoint.send("HeartRateTracker", "tracker_1717", msg);
switch (result) {
case Handled:
System.out.println("Message was delivered and handled.");
break;
case NotHandled:
System.out.println("Message was not handled.");
break;
}
Likewise, a C# application can deploy the wind turbine sample program as follows:
ExecutionEnvironmentBuilder builder = new ExecutionEnvironmentBuilder()
.AddDependency(@"WindTurbine.dll")
.AddDigitalTwin<WindTurbine, WindTurbineMessageProcessor, DeviceTelemetry>(WindTurbine.DigitalTwinModelType);
ExecutionEnvironment execEnvironment = await builder.BuildAsync();
A C# client application can then send a message to wind turbine instance “WT17” as follows:
SendingResult result = AppEndpoint.Send("WindTurbine", "WT17", jsonMessage);
if (result == SendingResult.Handled)
Console.WriteLine("Message was delivered and processed successfully");
else
Console.WriteLine("Failed to process message");
Client applications can deploy connectors using APIs in the client libraries as described in Deploying Connectors. A connector to the Azure IoT Event Hub is deployed using the C# client library, and connectors to AWS IoT Core, Azure Kafka, and Kafka are deployed using the Java client library.
Note
Widgets, queries, and other visualization features require the use of the UI and are currently not available in the APIs.