Training the Algorithm Using the ScaleOut Machine Learning Training Tool
Open the ScaleOut Machine Learning Training Tool, select ‘Train an ML.NET algorithm’ and click start.
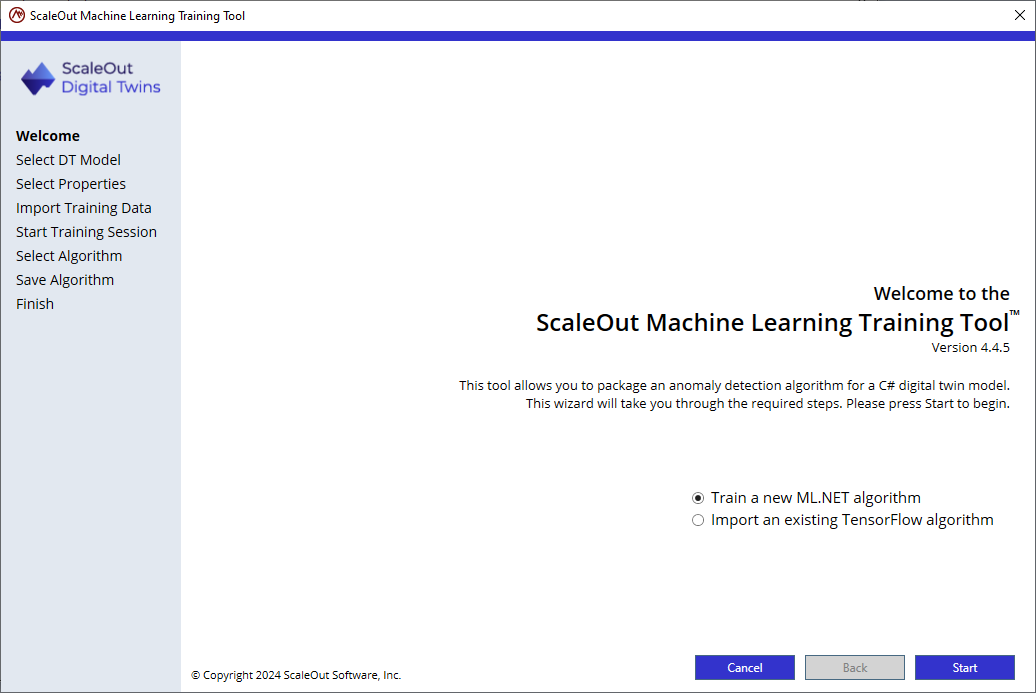
Select the file path to the directory containing the digital twin model’s binaries and scaleoutPackage.json file. It does not matter if the directory contains the final version of the model’s implementation as long as the properties the algorithm trains on remain identical. The wizard will use the scaleoutPackage.json file to determine the digital twin model’s name and the digital twin model’s DLL to extract available and supported properties.
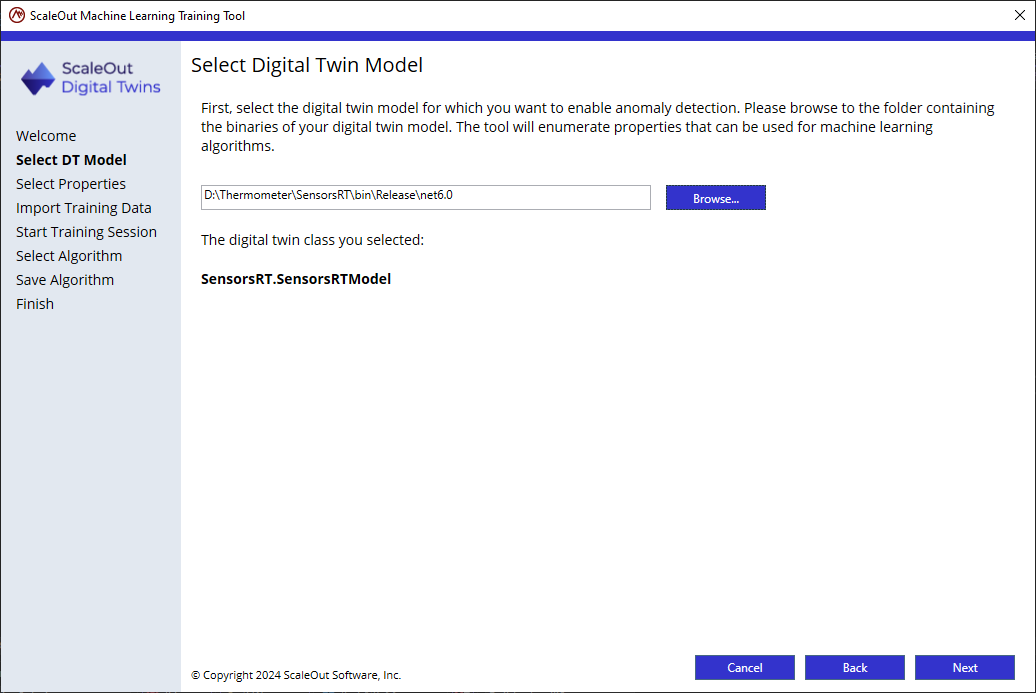
After making the selection, the wizard will show the digital twin model class that it located in the file path.
Click Next and select the properties to use for the machine learning algorithm. The tool suggests the digital twin properties of type float (or Single) by default. In this tutorial, the Temperature, Friction, and RPM properties are available and correspond to the properties used to train our algorithm, so all 3 are selected. Click Next.
Note
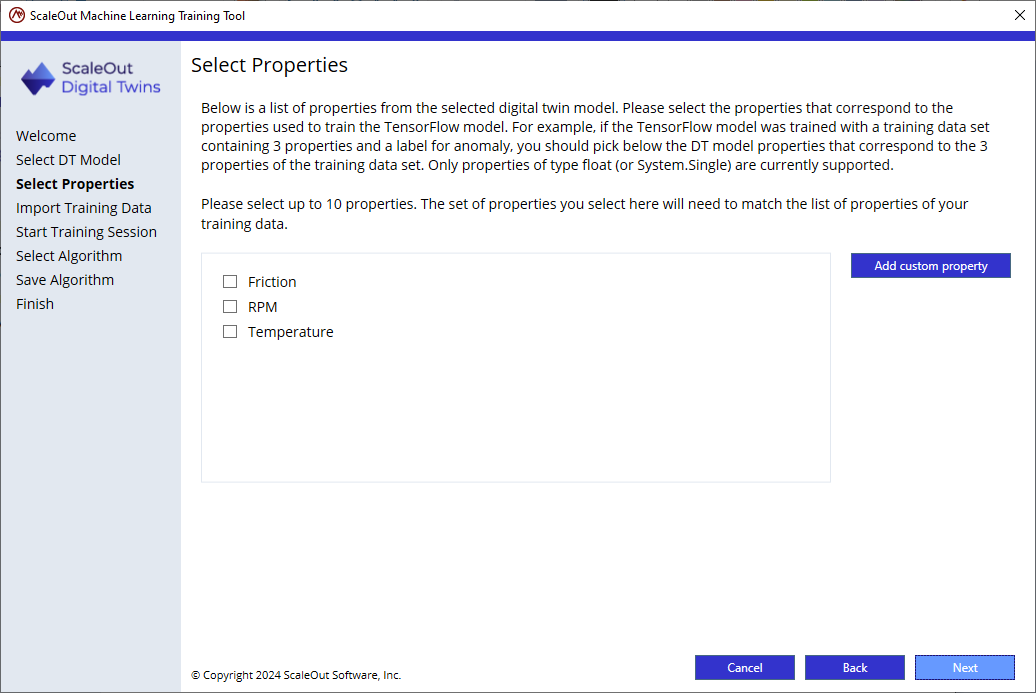
In some cases, you may need to use properties that are not defined as the digital twin model’s properties. This could be because you are using a nested property (property of a property of the class), or you are computing property on the fly. For example, if you have a digital twin model that defines properties for voltage and electric current, but the machine learning algorithm is trained using power (power is computed by multiplying voltage and electric current), you could add a custom property Power and use it for anomaly detection by clicking “Add custom property”.
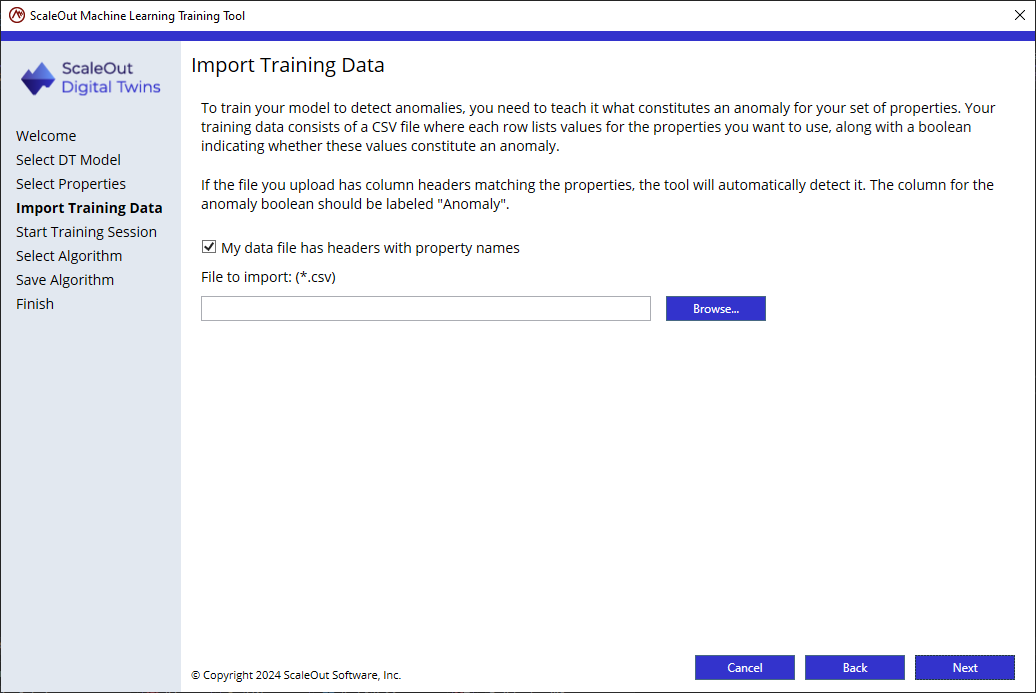
Click Next and provide the CSV file containing the training data.
Note
If the training dataset has headers, ensure that the headers match the property names defined in the Digital Twin model. The label column should be named Anomaly and contain true/false values.
The tool will attempt to match the columns to the properties of the model selected in the previous page and will display a preview of the first 10 rows of the training file for visually validating that the columns are matched to the appropriate properties.
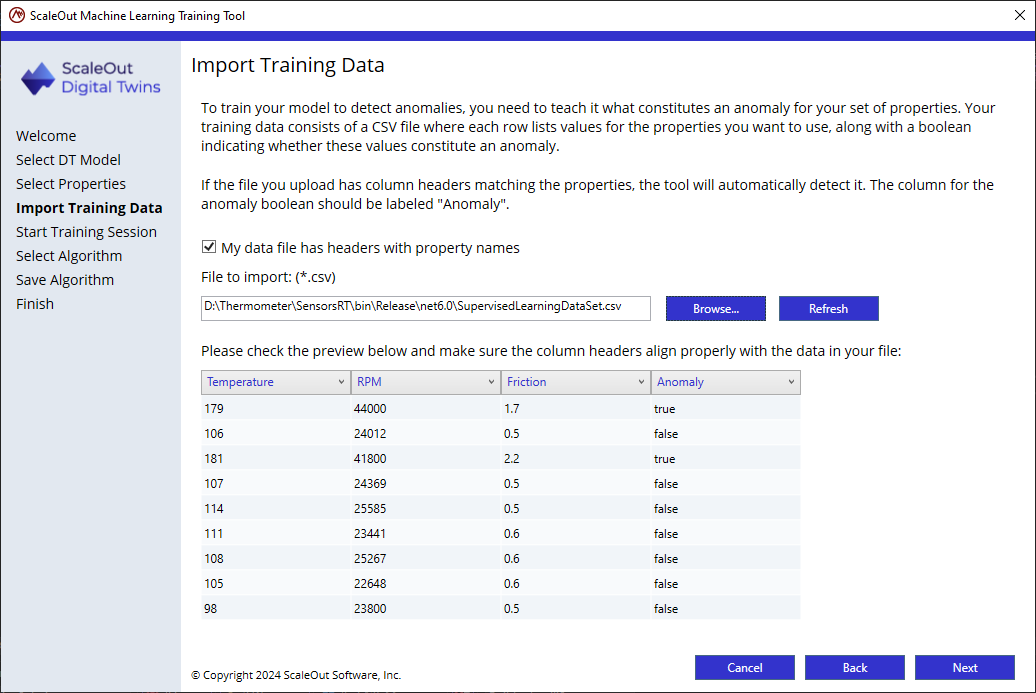
If necessary, reassign the columns to the appropriate properties. Not required if the file has headers matching the digital twin properties.
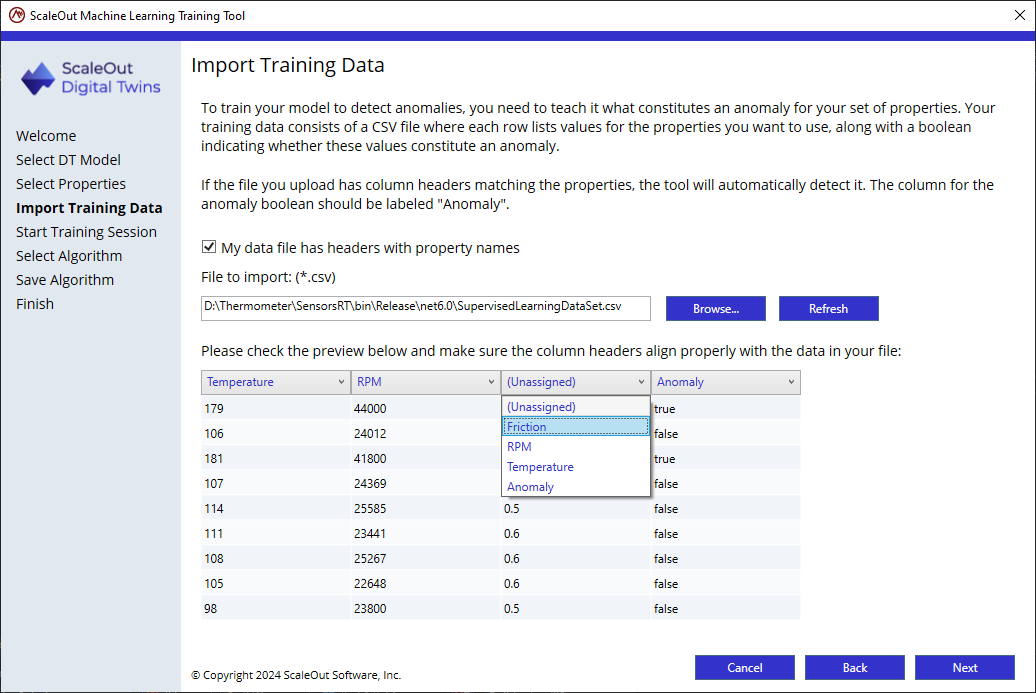
After verifying the column mappings, click Next and proceed to the next page.
Select the algorithms to train on the training set. After the training session completes, the wizard will show results for all algorithms to evaluate each algorithm’s performance.
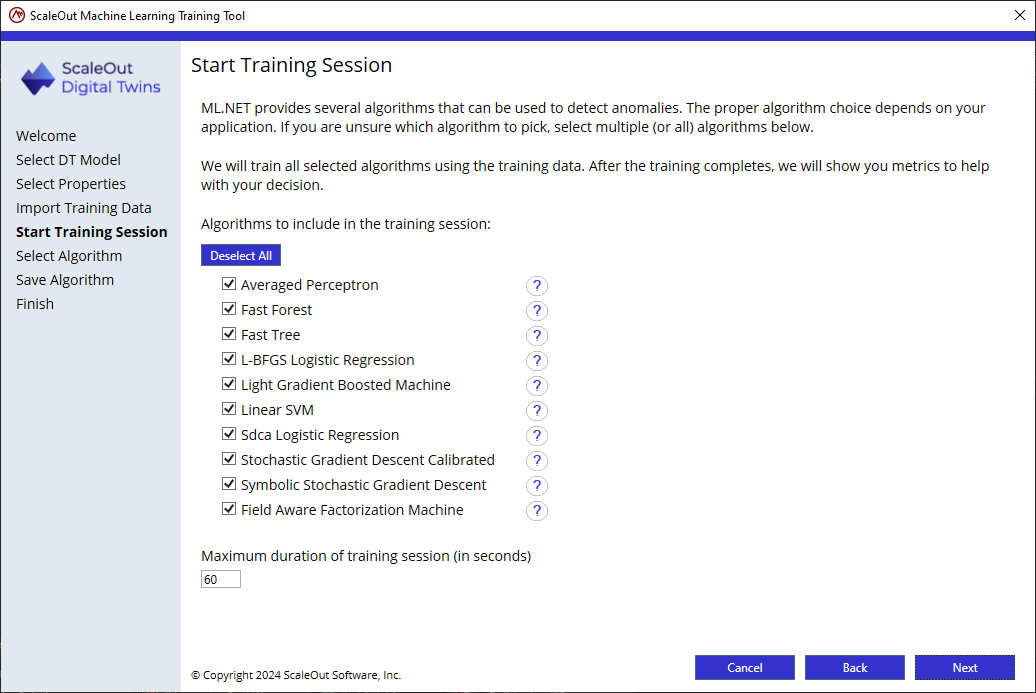
click Next to start the training session.
A portion of the data set (80%) is used for training while the remaining 20% is used for evaluating the trained algorithms. After training each algorithm, the wizard will display a table with metrics for each algorithm.
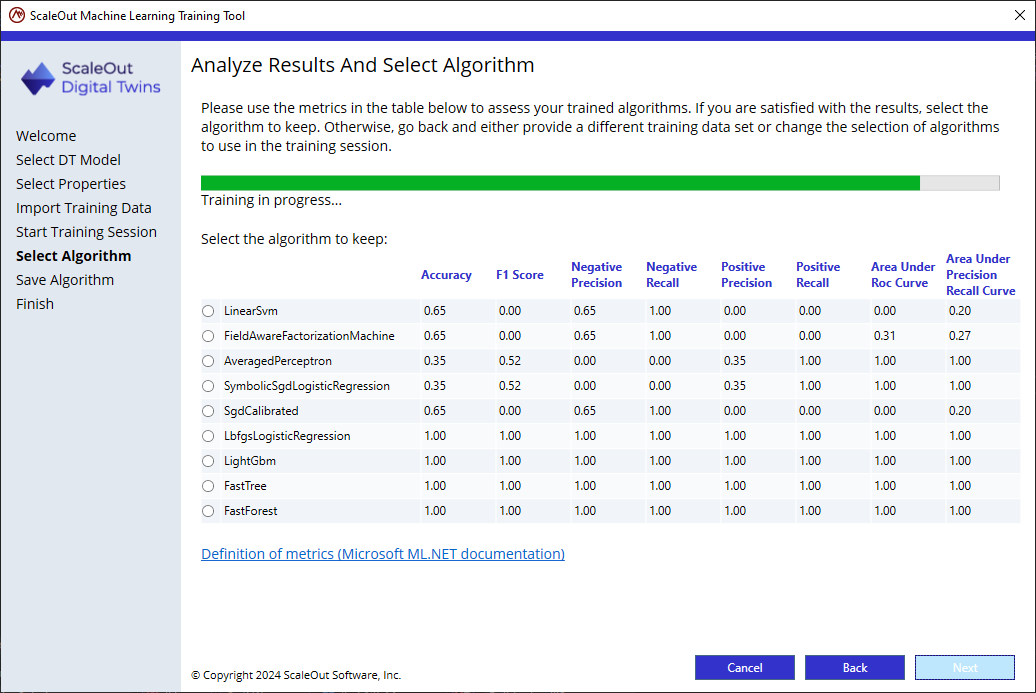
Select the algorithm that best matches the use case of the problem criteria and click Next.
Now save and package the trained algorithm so it can be used in a C# Digital Twin model.
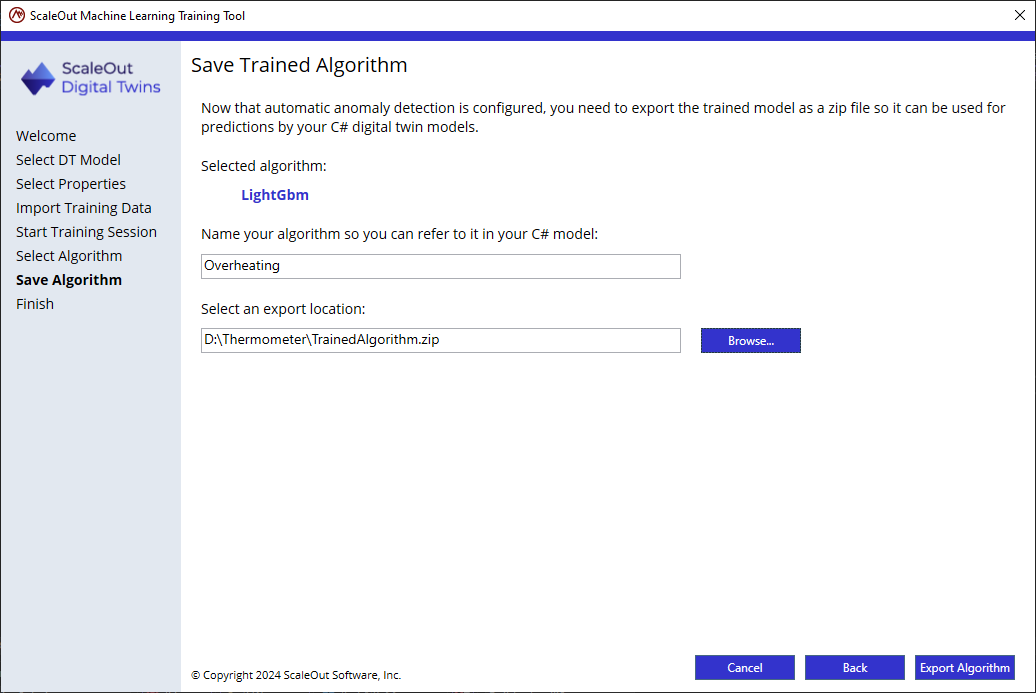
Name the algorithm: this is the name used by the C# MessageProcessor code to look up the trained algorithm. For this tutorial, use the name “Overheating”.
Select an export location: this is the location for the zip file that contains the trained algorithm. This zip file is deployed alongside the digital twin model.
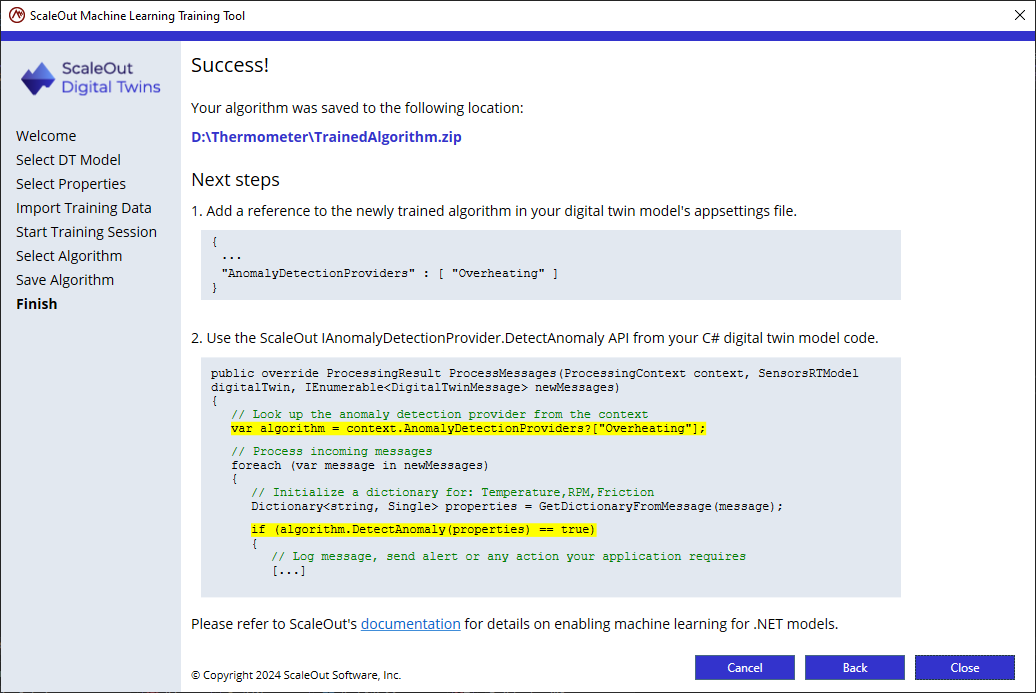
The last page shows you the modifications you need to do in your digital twin model solution to enable anomaly detection:
Provide the newly created zip file at deployment time along with your model
Look up the “Overheating” algorithm in the C# MessageProcessor code using the context, and call the DetectAnomaly API.