
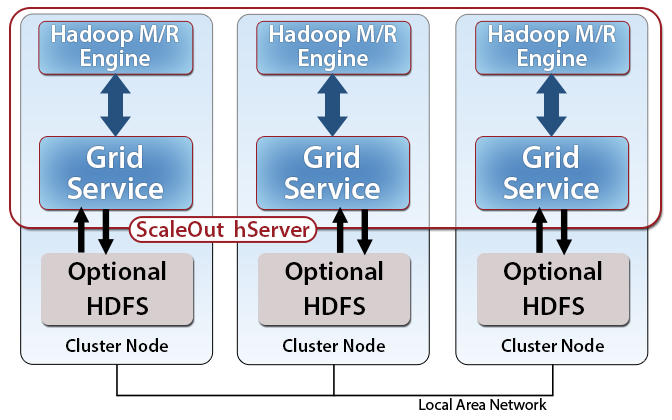
The ScaleOut hServer® Java API library integrates a Hadoop MapReduce execution engine with ScaleOut hServer’s in-memory data grid (IMDG). This open source library [1] consists of several components: a Hadoop MapReduce execution engine, which runs MapReduce jobs in memory without using Hadoop job trackers or task trackers, and four I/O components to pass data between the IMDG and a MapReduce job. The I/O components include the Named Map Input Format, the Named Cache Input Format, and the Grid Output Format, which together allow MapReduce applications to use the IMDG as a data source and/or result storage for MapReduce jobs. In addition, the Dataset Input Format accelerates the performance of MapReduce jobs by caching HDFS datasets in the IMDG.
Using ScaleOut hServer, developers can write and run standard Hadoop MapReduce applications in Java, and these applications can be executed stand-alone by ScaleOut hServer’s execution engine. The Apache Hadoop distribution does not need to be installed to run MapReduce programs; optionally, it can be installed to make use of other Hadoop components, such as the Hadoop Distributed File System (HDFS). (If HDFS is used to store data sets analyzed by MapReduce, ScaleOut hServer should be installed on the same cluster of servers to minimize network overhead.) ScaleOut hServer supports standard Apache Hadoop as well as third party distributions by Hortonworks and Cloudera. ScaleOut hServer’s execution engine offers very fast job scheduling (measured in milliseconds), highly optimized data combining and shuffling, in-memory storage of intermediate key/value pairs within the IMDG, optional use of sorting, and fast, pipelined access to in-memory data within the IMDG for analysis. In addition, ScaleOut hServer automatically sets the number of splits, partitions, and slots for IMDG-based data. Lastly, the performance of the Hadoop MapReduce engine automatically scales as servers are added to the cluster, and IMDG-based data is automatically redistributed across the cluster as needed.
Developers can use ScaleOut hServer’s Java APIs [2] to create, read, update, and delete objects within the IMDG. This enables MapReduce applications to input "live" data sets which are stored and updated within the IMDG. Complex IMDG-based objects can be stored within a named cache, which provides comprehensive semantics, such as object timeouts, dependency relationships, pessimistic locking, and access by remote IMDGs. These objects are input to MapReduce applications using the Named Cache input format. Alternatively, large populations of small key/value pairs can be efficiently stored within a named map, which provides highly efficient memory usage and streamlined semantics following the Java concurrent map model. These objects can be input to MapReduce applications using the Named Map input format. The Grid output format can be used to output objects from MapReduce applications to a named cache or a named map.
Note that some advanced features of the Java APIs, such as event handling, parallel query and parallel method invocation are only available under a full ScaleOut StateServer® or ScaleOut ComputeServer™ license.
This programming guide is intended to be a supplement to the Java API documentation and the ScaleOut StateServer (SOSS) Help File included with ScaleOut hServer. It focuses on the Java components used with Hadoop MapReduce applications.
Please refer to the ScaleOut StateServer help file for instructions on installing the IMDG service on a cluster of servers. ScaleOut hServer installs the ScaleOut StateServer grid service on all servers. When a MapReduce job is started, ScaleOut hServer automatically starts Java Virtual Machines (JVMs) on all servers (called an invocation grid) to implement its scalable Hadoop MapReduce engine.
The following "quick start" instructions for installing the IMDG on Linux will get you started. For each server in the cluster:
- Download the RPM file from the ScaleOut Software web site.
-
Install the RPM:
sudo rpm -ivh soss-5.4.1-253.el6.x86_64.rpm(It will be installed into /usr/local/soss5.) -
Verify the daemon is running:
soss query -
Configure the network settings to bind the grid service to the desired network, for example:
soss set net_interface=10.0.3.0 subnet_mask=255.255.255.0(You also can edit the soss_params.txt file in the installation directory and restart the daemon.) -
Join this server to the cluster of IMDG servers:
soss join
To install ScaleOut StateServer on Windows, download the appropriate installer from the the ScaleOut Software web site and follow the installation instructions. The server is installed as a Windows service and can be configured by using the SOSS Management Console.
The IMDG servers will automatically discover each other and balance the storage workload among all servers.
Sufficient physical memory should be provisioned for the IMDG to hold all data set objects and their associated replicas following the best practices described in the SOSS Help File. By default, named cache objects have one replica on a different server to ensure high availability in case a server fails. For example, if a 100GB data set is to be stored in the IMDG, this will require approximately 200GB of aggregate memory for the data set and its replicas (using the default parameters). If the cluster has four servers, this will require 50GB per server. Note that additional memory is required for object metadata and other data structures used by the IMDG. To maximize the performance of MapReduce applications, named map objects and intermediate key/value pairs do not use replicas; replicas optionally can be enabled for named maps (described below).
For MapReduce applications which input data from HDFS and store results in HDFS, the IMDG’s memory is only used to store intermediate results sent from the mappers to the reducers. If multiple grid servers are added to the cluster, their memory automatically is combined to store very large sets of intermediate results. Replicas are not used for intermediate results, and these results are cleared when a MapReduce job completes.
The Java API library for ScaleOut hServer can be found in soss-hserver-5.4-*.jar, and the Java API library for creating, reading, updating, and deleting objects can be found in soss-jnc-5.4.jar.
These jars and their dependencies are located in the java_api subdirectory of the ScaleOut StateServer installation directory.
ScaleOut hServer runs with several Hadoop environments, including those configured to run MapReduce on YARN, and it can serve as a MapReduce execution engine for Apache Hive (see configuration instructions).
If the MapReduce job running in ScaleOut hServer uses HDFS as the data input and/or output, it is necessary for the set of
library JARs on the client classpath to match the distribution of Hadoop used to run the HDFS data node(s) and name node(s).
Apache Hadoop 2.4.1 distribution-specific JARs are located in the ScaleOut hServer installation directory under java_api/hslib/hadoop-2.4.1. Additional distribution-specific JARs can be downloaded from the website at: http://www.scaleoutsoftware.com/support/support-downloads/. For convenience, a shell script to automatically download the JARs from the website is located in the ScaleOut hServer installation
directory under java_api/hslib/ (please see the included README for usage instructions). After downloading the JARs, move them to the installation folder
under java_api/hslib/. To run a ScaleOut hServer MapReduce job, the libraries in java_api/* and java_api/lib/*, and the distribution specific JARs should be included in the classpath on the invoking client.
ScaleOut hServer ships with support for the following Hadoop distributions:
| Distribution | Library path for java_api (JavaApi on Windows) |
|---|---|
Apache Hadoop 1.2.1 |
hslib/hadoop-1.2.1 |
Apache Hadoop 2.4.1 |
hslib/hadoop-2.4.1 |
CDH 4.4.0 |
hslib/cdh4.4.0 |
CDH 5 (MR1) |
hslib/cdh5.0.2 |
CDH 5 (YARN) |
hslib/cdh5.0.2-yarn |
CDH 5.2 (MR1) |
hslib/cdh5.2.1 |
CDH 5.2 (YARN) |
hslib/cdh5.2.1-yarn |
HDP 2.1 (YARN) |
hslib/hdp2.1-yarn |
HDP 2.2 (YARN) |
hslib/hdp2.2-yarn |
IBM BigInsights 3.0 |
hslib/ibm-bi-3.0.0 |
[1] The open source ScaleOut hServer Java API library (soss-hserver-5.4-*.jar) is licensed under the Apache License, Version 2.0 (http://www.apache.org/licenses/LICENSE-2.0).
[2] The ScaleOut StateServer Java API library (soss-jnc-5.4.jar) is licensed under the ScaleOut StateServer End User License Agreement.
