Recovery from Failures
To maintain high availability of its stored data, ScaleOut StateServer creates up to two replicas of every stored data object (up to three copies total as determined by the max_replicas parameter). These replicas are apportioned to other hosts so as to maintain the overall load-balance. The number of replicas per object depends on the number of available hosts:
# hosts |
# replicas per object |
|---|---|
1 |
0 |
2 |
1 |
>2 |
1 or 2, as specified |
All updates to an object are transactionally applied to its replicas using a patented, quorum-based updating algorithm. When a host fails or suffers a network outage, ScaleOut StateServer uses the replicas on other hosts to preserve stored data and to provide continued access to the affected objects. If a host suffers only a brief network outage, it resumes management of its objects once the outage has been corrected. Otherwise, in a process called self-healing, one of the replica’s hosts takes over management of each affected object, and an additional replica is created on another surviving host. (The failed host leaves the store.) Note that a host’s failure only affects the objects managed by that host; other objects usually remain continuously available during the recovery process.
Detecting Failures
ScaleOut StateServer uses periodic heartbeat packet exchanges between pairs of hosts to detect a network outage or host failure. To minimize overall networking overhead, ScaleOut StateServer uses a highly efficient heartbeat algorithm that limits the number of heartbeat exchanges per second so that overhead grows slowly with the number of hosts. Under normal conditions, the maximum network bandwidth consumed by a host to send heartbeat packets is less than 1K bytes/second.
Based on extensive evaluation of IP load balancing on server farms, ScaleOut StateServer uses a default heartbeat exchange rate of one heartbeat packet per 300 milliseconds. A host reports a possible outage if twenty consecutive heartbeat packets are not received from a remote host. This indicates that either one of the hosts has a network outage or the remote host has failed. Once an outage has been detected, the host begins a recovery process to isolate the problem and recover from a failure.
The Recovery Process
After a heartbeat failure occurs, all hosts engage in a recovery protocol to establish the currently responding membership. Hosts that do not respond because of server failures or network outages are dropped from the membership of the distributed store. This process takes approximately five to ten seconds after the heartbeat failure occurs. After the new membership is established, the hosts perform a self-healing process in which:
the hosts that are determined to have failed are removed from the membership,
lost copies of stored objects are replicated on other hosts to restore full redundancy (i.e., one or two replicas per object for farms with three or more hosts),
heartbeat exchanges are initiated between appropriate surviving hosts to replace the terminated exchanges, and
all hosts rebalance the storage load across the new membership. The self-healing and dynamic rebalancing process may require a minute or more to replicate the affected objects on new hosts, and this will temporarily slow the rate at which access requests to the affected objects can be handled.
ScaleOut StateServer heals its distributed store by creating new replicas for stored objects that were lost due to a server failure or network outage. This restores the full redundancy of the distributed store. If two or more servers are removed from the membership during the recovery process, some objects may be permanently lost. In this case, the store will return object_not_found exceptions for access requests to missing objects. (Please see the SOSS_DotNetAPI.chm online help file for details on access exceptions.)
Note
To maintain service whenever possible, ScaleOut StateServer attempts to self-heal and restore service even if no copies of an object still exist.
A host which suffers a network outage and cannot reach the network displays the isolated status and assigns all remote hosts an unknown status. (See the section Management Console for information on host status. The host suspends all handling of access requests until the network outage is corrected. This helps to maintain the consistency of stored data; see Split-Brain Failures below.
Note
A host becomes isolated when its connection to the network switch is unplugged, as shown in the following diagram. This will cause the host to suspend its handling of access requests, and other hosts may remove it from the membership. It may not be possible for the ScaleOut service to detect this condition under all situations, in which case the host will form an independent membership.
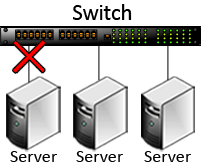
Once an active host can again reach the network, it determines if it is in the current membership. Remote hosts may have formed a new membership that excludes the host so that they can recover from the network outage. In this case, the host automatically restarts the StateServer service so that the host can rejoin the distributed store. This behavior ensures that an isolated host does not interfere with other hosts once a new membership has been formed.
Note
To enable recovery from switch failures, ScaleOut StateServer does not automatically restart an isolated host after it waits for a fixed recovery interval. Instead, it waits indefinitely for the network outage to be corrected and then determines whether to restart the StateServer service.
Handling Switch Failures
If all hosts are connected to the same network switch and the switch fails, the hosts attempt to enter and remain in an isolated status until the network outage is corrected. (If the operating system does not allow hosts to distinguish between a switch failure and network subnetting, they form independent memberships.) Once the switch resumes operations, the hosts determine whether the previously existing membership exists or has changed. If the switch restores service to all hosts within a few milliseconds, the hosts will detect each other before a subset of hosts can form a new membership. All hosts then will resume normal operation with the existing membership.
Some network switches sequentially enable individual ports over a period of several seconds after power is applied. In this case, a subset of hosts may form a new membership that excludes the remaining, disconnected hosts. As the switch adds new hosts to the network, these hosts may detect a newer membership and automatically restart the StateServer service. As a result of this switch behavior, stored data may be lost when the first set of hosts forms a new membership, and the distributed store can become destabilized.
You should always connect all hosts to the same network switch whenever possible. If the hosts are partitioned across two (or more) switches and the network link between the switches fails, the hosts on each switch will form separate memberships and continue operations, as shown in the following diagram:
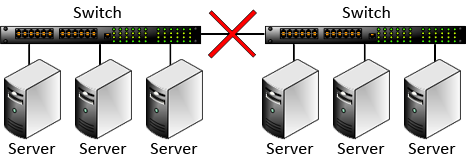
Once the network link between the switches has been restored, all hosts will detect the two memberships. To maintain the consistency of stored data (as explained below in Split-Brain Failures), one of the two memberships will survive, and all hosts in the other membership will automatically restart and rejoin the surviving membership.
Split Brain Failures
ScaleOut StateServer’s patented quorum-based updating technology ensures that updates are reliably committed to stored objects and their replicas. It does this by using a patented quorum-based update algorithm, which allows an update to be committed after at least two hosts (if available) are updated. This avoids the so-called split-brain problem inherent to primary/slave replication algorithms in which multiple copies are inconsistently updated.
Example of a Split Brain Failure
To see how the split-brain problem can occur, consider the two-server farm shown in the following diagram:

In this example, both hosts have a copy of object A, and they replicate updates to the local copy across the back-end network to the other host. The IP load balancer distributes updates from an Internet client to the hosts using the front-end network. If host 1’s back-end network interface fails after it receives update 1, it cannot communicate with host 2 to replicate its update. If host 2 then receives update 2, it updates its copy of object A without having received update 1, and it also cannot replicate update 2 back to host 1. The two copies of object A have different contents, and the hosts will return different results for read accesses to object A. Neither of the two hosts can determine whether it has the latest update because neither host can distinguish between a failure of the other host and a communications outage.
Note
The split-brain problem only manifests itself if a network outage occurs on ScaleOut StateServer’s network subnet and the front-end network continues to run normally. It will not occur if a host fails or if the front-end network also fails.
Isolated Hosts
ScaleOut StateServer’s patented, scalable quorum updating technology avoids the split-brain problem due to isolated hosts by employing a quorum update algorithm on server farms with two or more hosts and by suspending access requests to isolated hosts. Hence, a host in a multi-server farm never updates stored data unless it can perform a quorum update to one or both remote replicas. In the above example, ScaleOut StateServer would not accept the update on the isolated host, and the other host would not perform a quorum update until it could form a new membership that excluded the isolated host. This ensures that updates are never lost and that read accesses always return the result of the last update from the same client (following a “sequential consistency” model for ordering accesses).
Network Subnetting
If the hosts of a distributed store are partitioned across multiple network switches and the link between the switches fails, the split-brain problem can unavoidably arise due to network subnetting. Also, if the hosts cannot distinguish between a network link failure to the switch and other networking failures, it cannot isolate itself to avoid split-brain failures.
When network subnetting occurs, the hosts are isolated on different contiguous subnets. To maintain service to clients, they form independent memberships which simultaneously handle access requests; this is a split brain situation. Since quorum updates do not span multiple memberships, they cannot determine which membership has the latest updates. In fact, both memberships might have the latest updates for a different subset of objects.
When the network subnetting condition is eventually resolved, the hosts in two or more independent memberships detect the presence of multiple stores. To coalesce the hosts back into one membership, they allow one of the stores to survive, and the hosts in the other memberships restart and rejoin the surviving store. Restarting hosts may cause data to be lost, and this data may include the latest updates for some objects.
Because it cannot be determined which store contains the latest updates or has the preferred data, ScaleOut StateServer uses a heuristic to choose the surviving membership. It selects the store with the largest number of hosts, and if multiple stores have the same number of hosts, it chooses the one with the latest creation time. The goal of this heuristic is to minimize disruption to clients by restarting the fewest hosts.
Once all hosts have rejoined the surviving store, they rebalance the object load in this store and continue handling client load. Remote clients which were making access requests to the other stores will automatically detect host restarts and connect to the new membership.