Implementation of Redis Client Support
Overview
Targeted to meet the needs of enterprise users, ScaleOut In-Memory Database integrates open-source Redis code to provides support for popular Redis data structures and add important new capabilities for Redis user, including:
automated cluster management (that is, automatic creation, load-balancing, replication, and recovery for hashslots),
fully consistent updates for Redis commands (versus eventally consistent updates implemented by open-source Redis) to ensure reliable data storage even after server failures,
multi-threaded execution of commands using all available processing cores to eliminate the need for multiple shards per server.
Redis clients can run alongside native ScaleOut StateServer clients within the same cluster and make use of ScaleOut StateServer’s management tools.
Integration of Open-Source Redis Code
ScaleOut In-Memory Database incorporates Redis open-source code (version 6.2.5 in the current release) to implement Redis data structures and commands. This ensures that Redis commands return identical results as an open-source Redis server. Clients connect to ScaleOut In-Memory Database exactly as they would to any Redis deployment using the same RESP wire protocol.
The following diagram shows how Redis open-source code has been integrated into ScaleOut In-Memory Database:

Redis open-source code (shown in the red box) implements command parsing and processing, the data structure commands, transactions, publish/subscribe commands, and utility commands. ScaleOut In-Memory Database takes over all clustering functions, including request processing, membership, quorum processing of updates, load-balancing, recovery, and self-healing. It also uses a proprietary transport protocol for server-to-server communication.
Client-Server Protocol
Redis clients connect to any ScaleOut In-Memory Database server in a cluster using the standard RESP protocol. (A ScaleOut cluster can contain one or more servers.) Client libraries internally obtain the mapping of hashslots to servers using either the CLUSTER SLOTS or CLUSTER NODES commands and then direct Redis access requests to the appropriate ScaleOut server. They use the Redis -MOVED error code when running Redis commands to detect when hashslots have moved to a different server and to redirect their requests. ScaleOut In-Memory Database servers stall pending Redis commands while hashslots are in motion to ensure that they are ready to process client requests after the -MOVED error is returned. This avoids client exceptions that can occur if redirected commands arrive at a server before the targeted hashslot is online.
To ensure fully consistent updates to Redis objects, ScaleOut In-Memory Database does not support the -ASK error and the importing/exporting states for hashslots. Instead, ScaleOut In-Memory Database stalls Redis commands while hashslots are in motion and returns -MOVED errors when the affected hashslots are ready to handle client requests at their destination hosts. This mechanism also avoids exceptions from the client library that otherwise could occur during hashslot migration.
Automated Cluster Management
ScaleOut In-Memory Database uses one service process per server to host both primary and replica hashslots, as illustrated below:
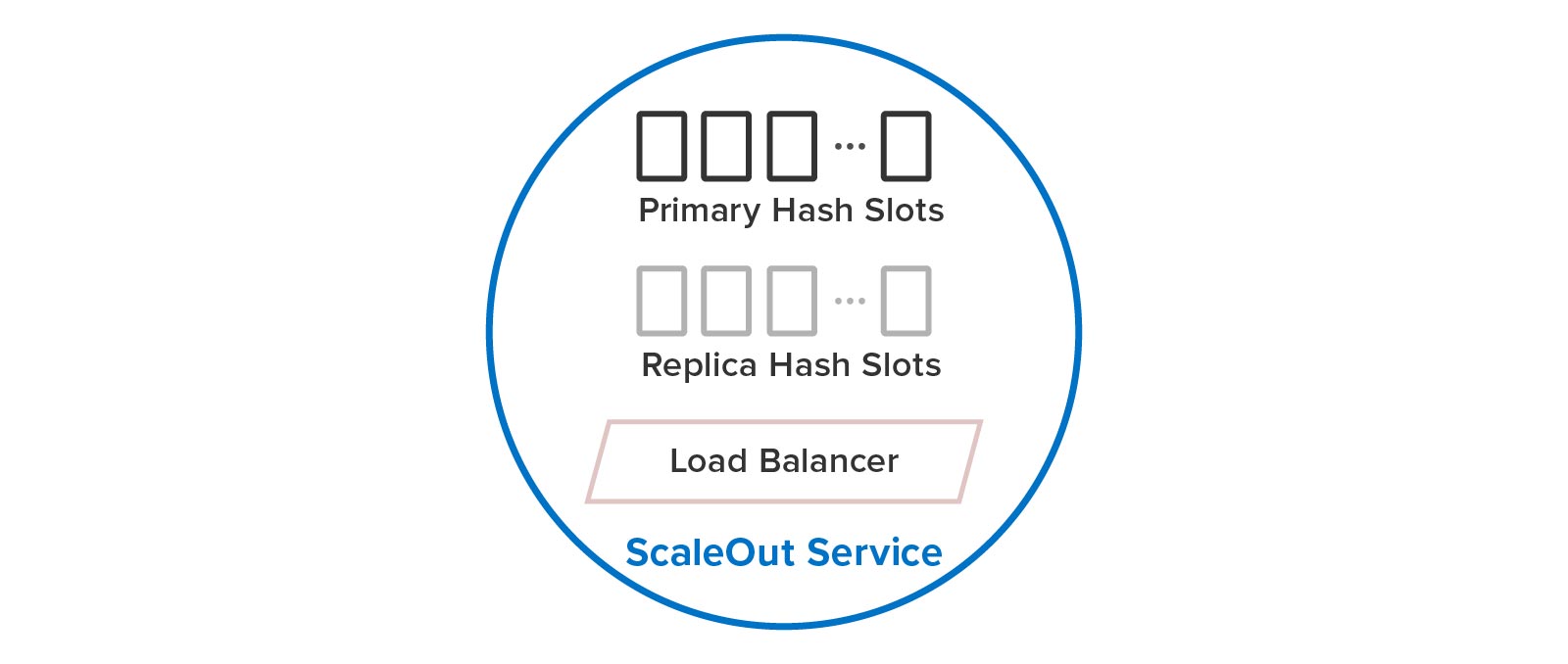
When an additional server is needed to boost throughput, it can be added by starting the StateServer service process on a new server and joining it to the cluster:

The cluster automatically rebalances the workload so that each server has a proportional share of both primary and replica hashslots. Load-balancing and data replication require no actions on the part of the user. The following diagram illustrates how ScaleOut In-Memory Database automatically manages hashslots. In this example, it migrates half of the hashslots to a second server that joins a cluster with a single server:

For each hashslot, ScaleOut In-Memory Database maintains at least one replica on a separate node. For example, in the above diagram showing a two-node cluster, both nodes have copies of each other’s hashslots to ensure full redundancy. When additional servers are added, ScaleOut In-Memory Database automatically redistributes both the primary and replica hashslots to maintain both load-balance and redundancy.
ScaleOut In-Memory Database uses a coherent cluster membership with built-in, adaptive heart-beating that adjusts to the speed of the network. When it detects a missing server due to a failure or network outage, it automatically “self-heals” by creating a new cluster membership, promoting and duplicating replicas as needed, and rebalancing the workload on the surviving servers. It also detects and recovers from network subnetting (sometimes called a “split brain” configuration).
Fully Consistent Updates
Distributed caches keep replicas for all stored objects to maintain high availability. If a server goes down or gets disconnected from the network, one or more other servers have a copy of the data and can step in to serve client requests. To make this work reliably, the distributed cache needs to keep all replicas of each stored object consistent after an update. Otherwise, a failure could occur and cause the latest updates to be permanently lost.
Redis clusters use an eventual consistency algorithm for updating stored objects. This approach is relatively simple and it allows for the maximum possible throughput. However, it is susceptible to data loss because it does not guarantee that all replicas are consistently updated.
To avoid this problem and ensure reliable data storage, ScaleOut In-Memory Database uses a patented quorum algorithm to implement fully consistent updates to stored objects using a sequential consistency algorithm. (For applications that need to maximize throughput at the expense of data consistency, ScaleOut In-Memory Database can optionally be configured for eventual consistency.) When a server receives a Redis command, it executes this command on a quorum containing the primary hashslot and its replicas (one or two in the current implementation) prior to returning to the client. Redis transactions are processed in the same manner.
To illustrate the importance of fully consistent updates, the following diagram shows a Redis command updating a primary and replica copy of a stored object using Redis’s eventual consistency algorithm:
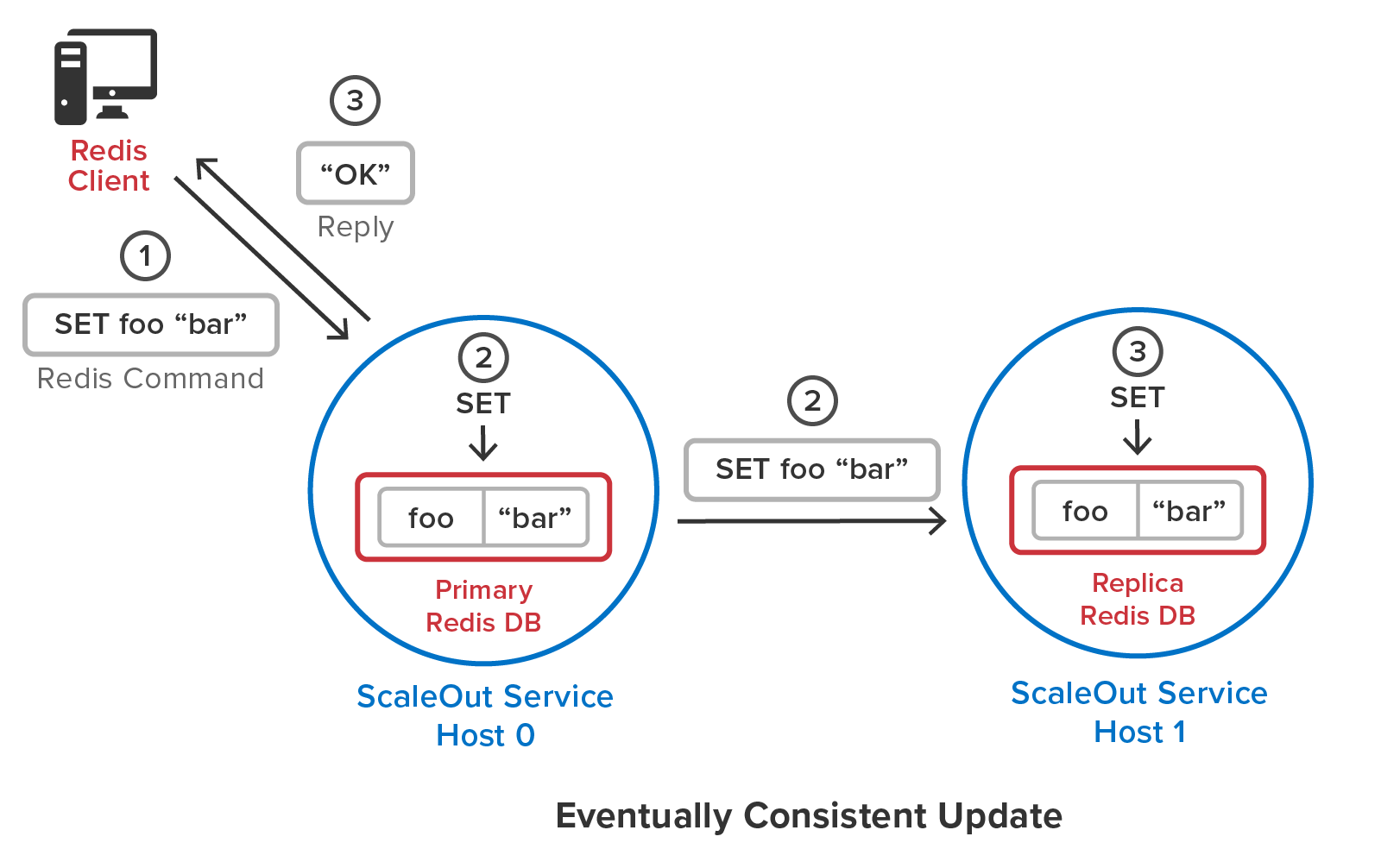
If the primary server (or the network link to its replica server) fails while sending the update to its replica but after it replies to the client, the update will be lost, and the client will be unaware of the problem.
ScaleOut In-Memory Database avoids this problem by awaiting completion of updates to a quorum (i.e., majority) of copies of the data prior to replying to the client. This ensures that updates survive the failure of any server, and the cluster reliably stores the data. The following diagram shows how this algorithm awaits a response from the replica prior to responding to the client when one replica is used:
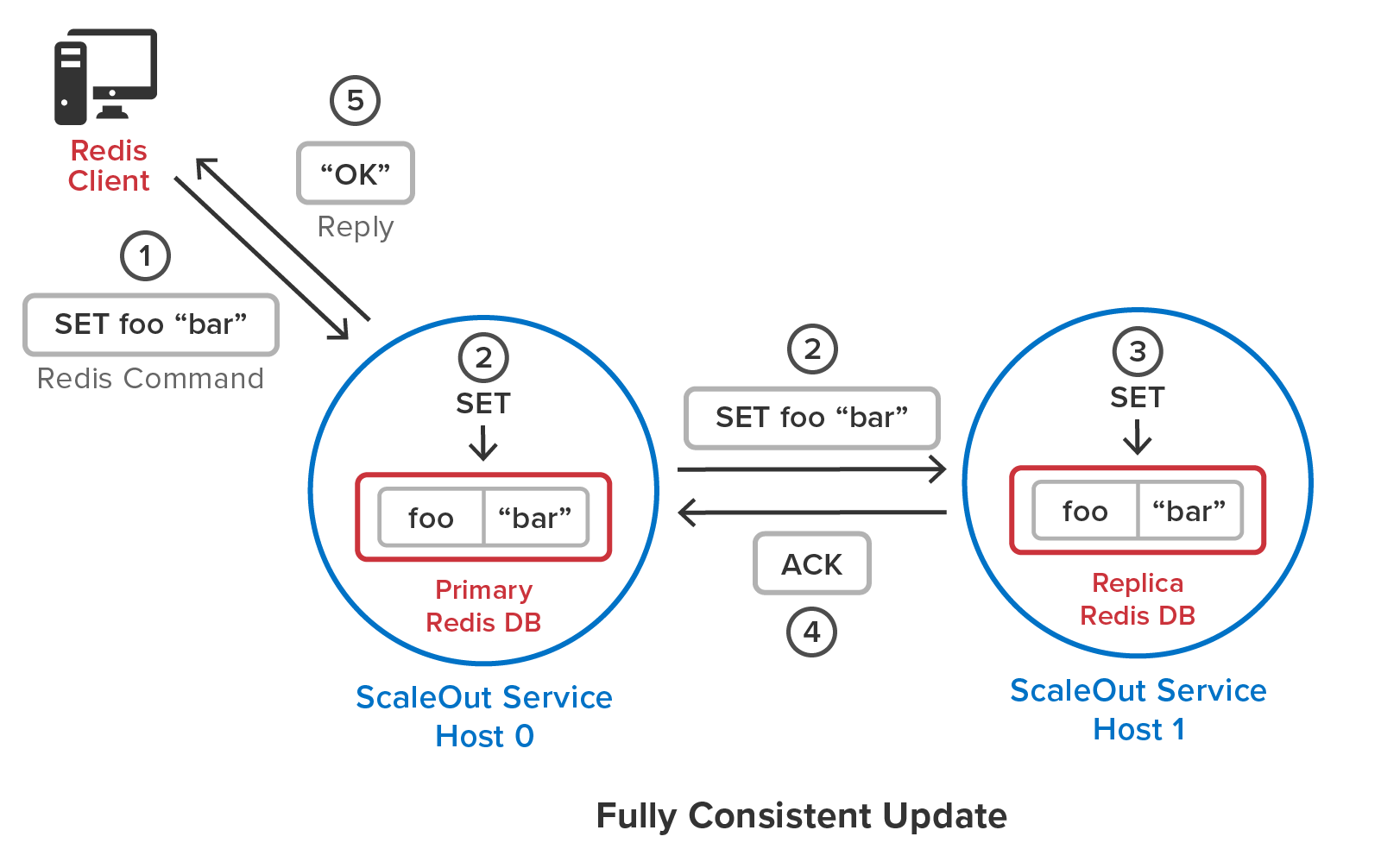
ScaleOut’s patented quorum algorithm for updating replicas was designed to deliver the best combination of data consistency and throughput to meet the needs of enterprise applications. It ensures that updates to mission-critical data are always reliably stored while providing high throughput by only waiting for a quorum of replicas to be updated prior to returning to the client.
Multi-Threaded Command Processing
Redis uses a single-threaded, event-loop software architecture to execute commands. While this approach eliminates locking, it constrains throughput to that provided by a single processing core. To overcome this limitation and enable the use of multiple cores per server, Redis lets system administrators deploy multiple “shards” (service processes) per node and distribute the hashslots across them. This approach can be complex to manage and can increase costs.
ScaleOut In-Memory Database uses multi-threaded execution for Redis commands to automatically take advantage of all processing cores and eliminate the need for multiple primary shards on each server. As commands flow in to each service process for different hashslots, ScaleOut In-Memory Database executes them independently and in parallel on all available processing cores. ScaleOut’s multi-threaded architecture delivers the maximum possible throughput combined with reliable data storage using a single, self-managed service process on each node.
The following diagram shows the difference between Redis’s event-loop design and ScaleOut’s multi-threaded design:

ScaleOut In-Memory Database’s highly integrated design enables each service process to automatically perform all clustering functions while delivering multi-threaded speedup for Redis commands. Designed for enterprise users, it enables system administrators to minimize management costs and lower TCO.