Overview of ML Techniques
In complex systems with thousands of data sources and telemetry values to watch, ML techniques can help point out where an error is occurring. It can outperform humans in identifying potential issues quickly. It can also help to lower costs by detecting issues early and allowing fast resolution or by predicting and avoiding major issues.
The ScaleOut Digital Twins™ service offers two categories of machine learning and statistical analysis:
Spike and trend change detection for an individual numeric property using unsupervised learning and statistical techniques
Anomaly detection for sets of numeric properties using supervised learning
The predictive power of machine learning can be combined with alert providers to automatically monitor thousands of data sources and trigger alerts when anomalies are detected. The real-time digital twin model can be configured to automatically send alerts or add events to an event list if a spike, trend change, or anomaly is detected. For each new received message, the spike and trend change algorithms can signal an alert within a few milliseconds, allowing for very quick action. These algorithms run independently in all real-time digital twins, enabling them to simultaneously track thousands of data sources.
Spike and Trend Change Detection
Spikes are sudden and temporary changes in a property’s value, such as a voltage spike. They may indicate a situation that requires a fast response. Trend changes are slow but unexpected changes that take place over a period of time, such as a gradual increase in oil temperature that should remain stable. These changes can be tricky to notice if not closely monitored.
The ScaleOut Digital Twins service allows users to track spike and trend changes both for individual model properties or message properties (that is, telemetry values). The service detects spikes using an unsupervised learning algorithm in ML.NET called adaptive kernel density estimation. It detectes trend changes using a linear regression algorithm. Both algorithms keep several recent data points to enable detection when a new message is received from the data source.
Here is an example of a spike:
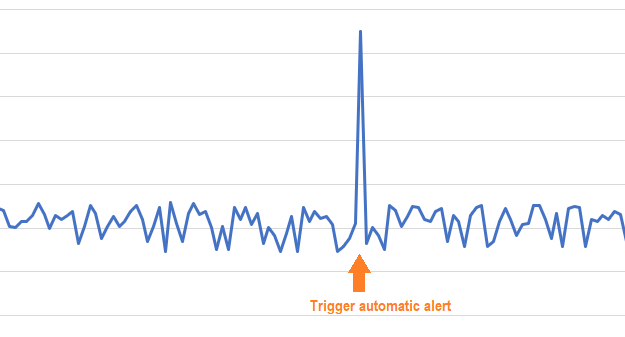
Trend change detection detects inflection points based on historical values and requires that several data points be examined before an alert is triggered. The algorithm’s sensitivity is configurable so that users can adjust it based on their experience.
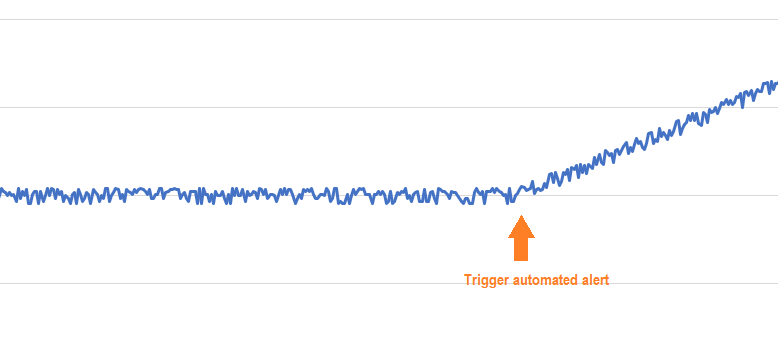
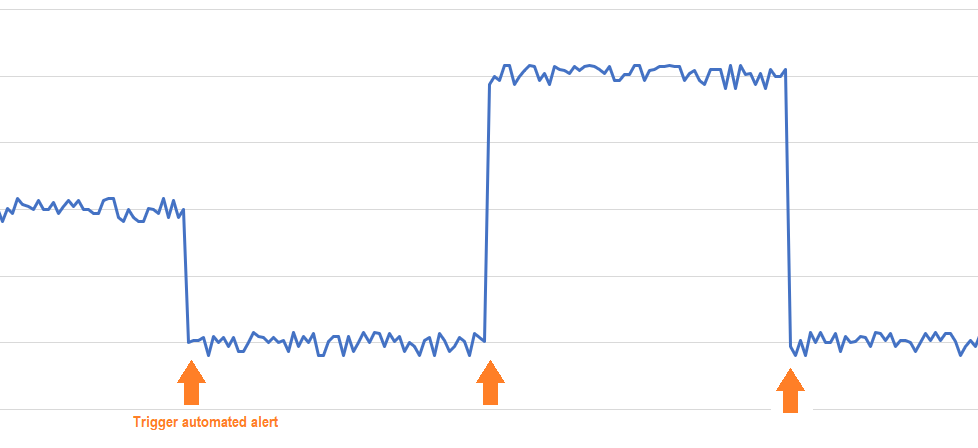
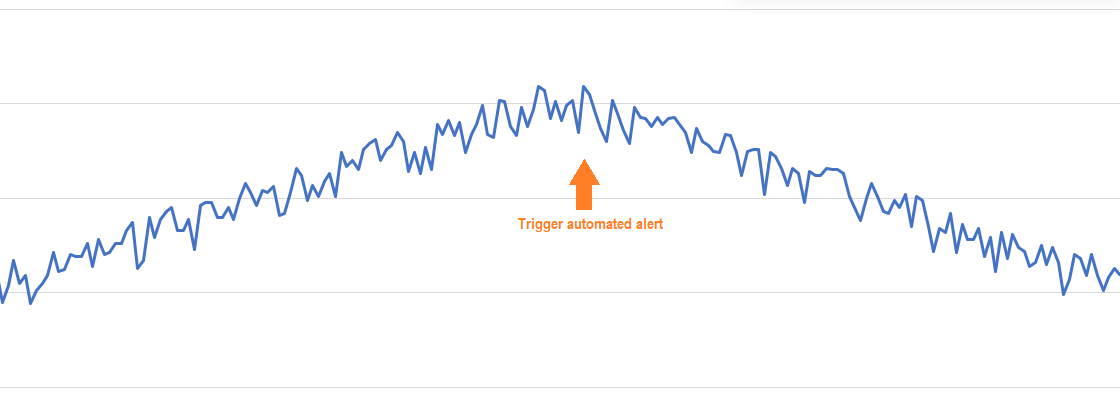
Here are examples of three types of trend changes that the algorithm can identify.
Example of ramp-up, ramp-down, or level-off:
Example of shift in the mean value:
Example of ramp inversion:
Anomaly Detection with Supervised Learning
Anomaly detection in machine learning is a process that identifies outliers for a set of values, such as a combination of engine parameters (e.g, oil temperature, RPM, and exhaust gas temperature). It employs supervised machine learning, which requires training with a dataset that labels normal and abnormal value combinations. The trained algorithm can then be used to predict anomalies when each real-time digital twin receives messages from its data source.
Digital twin models can import trained TensorFlow algorithms to predict anomalies. The training of such algorithms is done externally using traditional methods, and the import can be performed either through the ScaleOut Model Development Tool (for rule-based models) or through the ScaleOut Machine Learning Training Tool (for C# models).
Digital twin models also incorporate Microsoft’s ML.NET machine learning library to enable the use of ten supervised learning algorithms for binary classification. Prior to deploying the model to the ScaleOut Digital Twins service, you can first train and evaluate several algorithms by supplying a dataset with historical values that have been classified as normal or abnormal. You can then compare the performance of these algorithms using established criteria and select one trained algorithm for deployment in the model.
Providing the Training Data
To train your ML algorithm to identify outliers, you first provide a dataset in a standard comma-separated values (CSV) file that lists in each row a set of sample values and labels each set as normal or abnormal. This enables training for the candidate ML algorithms so that they can identify abonormal sets of values. For example, if your data collection has four properties, the CSV file needs five columns, one for each property and one column that labels each row with a TRUE (anomaly) or FALSE (normal) value.
For example, if a data collection has three properties Temperature, RPM, Friction, it would look like this:
When training an ML algorithm, the ScaleOut Model Development Tool will split the training data set in two subsets: one for training (80% of the original file) and one for testing (the remaining 20%). After training, the tool evaluates each algorithm using the testing subset to assess the effectiveness of its training.
Selecting Algorithms to Train
The ML algorithms used for anomaly detection are called binary classification algorithms because they classify the elements of a set into two groups (normal or abnormal in this case). ML.NET offers many binary classification algorithms, and each algorithm has characteristics that make it better suited for specific applications. You can select one or more algorithms for training and evaluation to find the best fit for your application.
Here are the ML.NET binary classification algorithms that can be used in the ScaleOut Digital Twins service:
AveragedPerceptron : linear binary classification model trained with the averaged perceptron
FastForest : decision tree binary classification model using Fast Forest
FastTree : decision tree binary classification model using FastTree
LbfgsLogisticRegression : linear logistic regression model trained with L-BFGS method
LightGbm : boosted decision tree binary classification model using LightGBM
LinearSvm : linear binary classification model trained with Linear SVM
SdcaLogisticRegression : binary logistic regression classification model using the stochastic dual coordinate ascent method
SgdCalibrated : logistic regression using a parallel stochastic gradient method
SymbolicSgdLogisticRegression : linear binary classification model trained with the symbolic stochastic gradient descent
FieldAwareFactorizationMachine : field-aware factorization machine model trained using a stochastic gradient method
Averaged Perceptron
The averaged perceptron algorithm is an extension of the standard perceptron that updates the model’s weights based on misclassified examples during training, but instead of using the final weight vector, it averages all the weight vectors from each iteration to reduce variance and improve prediction accuracy.
See also
Fast Forest
The Fast Forest classification algorithm is an ensemble method that constructs a large number of decision trees using random feature subsets at each split, and accelerates training and prediction by employing techniques like data binning and histogram-based node splitting, making it well-suited for large-scale and high-dimensional data classification tasks.
See also
Fast tree
The Fast Tree classification algorithm is a gradient boosting method that builds an ensemble of decision trees in a stage-wise manner, optimizing for both speed and accuracy by using efficient histogram-based techniques for finding optimal split points, making it particularly effective for large datasets with high-dimensional features.
See also
L-BFGS Logistic Regression
L-BFGS Logistic Regression is an optimization-based classification algorithm that uses the Limited-memory Broyden-Fletcher-Goldfarb-Shanno (L-BFGS) method to efficiently handle large-scale datasets by approximating the inverse Hessian matrix to find the optimal weights for the logistic regression model.
See also
Light Gradient Boosted Machine
Light Gradient Boosted Machine (LightGBM) is a highly efficient gradient boosting framework that uses a histogram-based learning method, optimized for speed and memory usage, and is particularly well-suited for handling large-scale datasets with high dimensionality and complex patterns.
See also
Linear SVM
The Linear SVM algorithm is a supervised learning method that finds the optimal hyperplane to linearly separate data into classes by maximizing the margin between the closest points of the classes, making it effective for binary classification tasks with linearly separable data.
See also
Sdca Logistic Regression
Sdca Logistic Regression is a scalable classification algorithm that uses Stochastic Dual Coordinate Ascent (SDCA) to efficiently optimize the logistic loss function, making it suitable for large-scale and sparse datasets.
See also
Stochastic Gradient Descent Calibrated
Stochastic Gradient Descent Calibrated (SGD Calibrated) is an iterative optimization algorithm that combines stochastic gradient descent with an additional calibration step, such as Platt scaling, to improve the probability estimates of linear classifiers for better predictive accuracy.
See also
Symbolic Stochastic Gradient Descent
Symbolic Stochastic Gradient Descent is a variant of stochastic gradient descent that leverages symbolic computation to optimize the training of machine learning models by efficiently managing and computing gradients through symbolic expressions. It makes its predictions by finding a separating hyperplane.
See also
Field Aware Factorization Machine
Field Aware Factorization Machine is a machine learning model designed to capture interactions between features in different fields, enhancing predictive performance by incorporating field-specific factorization in addition to general feature interactions.
See also
Analyzing Model Metrics
After the candidate ML algorithms you select have been trained, ML.NET tests them for evaluation using the testing data subset. This produces a set of metrics that can you can use to pick the best algorithm for your application. It is important to understand how to evaluate an algorithm as you go through the training process. While the accuracy of a trained model is an important metric, other metrics, such as precision and recall, should also be evaluated for each application to avoid issues like false positives.
Please refer to the Microsoft ML.NET documentation to understand the different metrics produced by ML.NET that the tool will compute and display after the candidate ML algorithms you select have been trained.
Definition of metrics used by Microsoft ML.NET
See also
Training ML Algorithms And Getting Predictions
The training of ML.Net algorithms or import of trained TensorFlow algorithms to predict anomalies can be performed either through the ScaleOut Model Development Tool (for rule-based models) or through the ScaleOut Machine Learning Training Tool (for C# models). Those sections also detail how to use those algorithms to obtain predictions.