Overview
ScaleOut In-Memory Database™
ScaleOut In-Memory Database combines ScaleOut StateServer’s cluster architecture with the popular, open-source Redis database. Targeted to enterprise Redis deployments that need to keep TCO to a minimum, this product provides fully automatic cluster management that eliminates the need to provision shards and hashslots. System administrators just add servers to increase in-memory storage throughput as the workload grows. ScaleOut’s cluster architecture automatically creates replicas and distributes the workload across the cluster. It also detects and handles server failures by rebalancing the cluster and creating missing replicas to “self-heal.”
Note
ScaleOut In-Memory Database runs on a ScaleOut StateServer cluster and use its management tools. Your license key enables ScaleOut In-Memory Database’s features, which also include all features available in ScaleOut StateServer. Both a Redis database and ScaleOut StateServer objects can simultaneously be stored on a ScaleOut cluster.
ScaleOut In-Memory Database provides these key new capabilities for Redis applications:
automated cluster management (that is, automatic creation, load-balancing, replication, and recovery for hashslots),
fully consistent updates for Redis commands (versus eventally consistent updates implemented by open-source Redis) using patented quorum technology to ensure reliable data storage even after server failures,
multi-threaded execution of commands using all available processing cores to eliminate the need for multiple shards per server.
one-touch, fully parallel backup and restore using ScaleOut’s management tools
deployment on both Linux (Red Hat and Debian/Ubuntu) and Windows servers
ScaleOut In-Memory Database includes support for all popular Redis data structures and several utility commands. To ensure that Redis commands provide results that are identical to open-source Redis servers, ScaleOut In-Memory Database integrates open-source Redis code (version 6.2.5) into its cluster architecture. Redis clients connect to ScaleOut StateServer using same RESP wire protocol as they do for Redis servers. The current release includes support for the following Redis data structures and additional commands:
string commands (for example, SET)
list commands (for example, LPUSH)
set commands (for example, SADD)
hash commands (for example, HSET)
sorted set commands (for example, ZADD)
pubsub commands (for example, PUBLISH)
stream commands (for example, XADD)
hyperloglog commands (for example, PFADD)
geospatial commands (for example, GEOADD)
transactions (for example, MULTI, EXEC, and WATCH)
utility commands: FLUSHALL, FLUSHDB, EXPIRE, EXPIREAT
cluster commands: CLUSTER NODES, CLUSTER SLOTS, and CLUSTER INFO
Note
The flush commands clear the Redis database on all hosts (not just a single server). Likewise, the PUBLISH command operates globally by multicasting to all cluster hosts.
Note
Lua scripting, streams, modules, AOF/RDB persistence, and other Redis features are not included in this release.
Redis clients can run alongside native ScaleOut StateServer clients within the same cluster and make use of ScaleOut StateServer’s management tools.
Note
Do not use Redis cluster commands to manually reconfigure a ScaleOut In-Memory Database cluster. Instead, use ScaleOut’s management tools, as described in the section Management.
You can learn how to configure Redis clients in the Installation section Configuring Redis Clients, and you can read about how Redis client support is implemented under Theory of Operation in the section Implementation of Redis Client Support.
ScaleOut StateServer®
ScaleOut StateServer provides a software-based, distributed, in-memory data grid, simply called a store and often referred to as distributed cache, for mission-critical workload data. Intended for use within a data center, the software is installed as a Windows service or Linux daemon on all servers within your Web or application server farm, and uses your Web farm’s existing LAN. The software stores, reads, updates, and removes contiguous, opaque, binary data objects such as session-state, e-commerce shopping carts, cached DBMS data, and business logic state, based on an identifying 256-bit key. These data objects either have been serialized from datasets or record sets that were previously accessed from a database or are generated as application objects. Stored objects can be uniformly accessed from any server in the farm.
The following diagram shows ScaleOut StateServer installed on a Web farm with four servers:
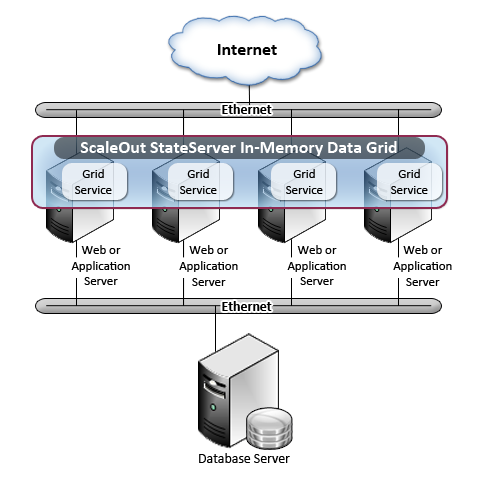
Once installed and configured, ScaleOut StateServer provides fast, scalable in-memory storage for applications by saving and retrieving objects using powerful, easy-to-use APIs. It also operates in a transparent manner to Microsoft ASP.NET applications by saving and retrieving session-state objects for Internet clients. Under normal operations, the software automatically balances the amount of storage used by each server in the farm, adjusting the relative usage by each server to the amount you specify. To ensure highly available access, up to three copies of each stored object are transparently maintained on different servers; by default, two copies are stored. If a server fails or loses network connectivity, ScaleOut StateServer automatically retrieves its session objects from replicas stored on other servers in the farm, and it creates new replicas to maintain redundant storage. When an offline server later rejoins the farm, it automatically regains its share of the storage workload.
As new servers running ScaleOut StateServer are added to the Web farm, they automatically expand the IMDG’s storage capacity and scale its aggregate throughput once enough servers have been added to hold all replicas. This helps ensure that fast response times are maintained even as the Web farm grows to handle increasing load.
In summary, the key features of ScaleOut StateServer include:
self-discovery and self-aggregation of servers within a farm,
uniform access to stored data objects from any server in the farm,
scalable throughput as servers are added (beyond the minimum number needed to hold all replicas) and the storage load grows,
automatic partitioning and dynamic load-balancing of data objects among participating servers to maximize scalability,
fully coherent, local (client-side) caching of recently used objects to minimize access times,
automatic, intelligent replication of data objects on up to three servers to provide high availability,
automatic detection of host and communication failures followed by fast recovery for single failures,
recovery usually without data loss after failure of any one or two servers (for farms with three or more servers and depending on the number of replicas specified),
automatic self-healing to restore data redundancy after permanent server failures,
highly available operation even after failure of N-1 servers within an N server farm,
fine-grained control of network usage that adapts to slow networks and virtualized servers,
transparent storage of ASP.NET session-state objects without programming changes,
programmatic access to the store with asynchronous event handling for .NET, Java, and unmanaged C/C++ applications,
programmatic access to the store for HTTP-enabled applications via a REST API service,
support for Redis data structure commands, pubsub commands, transactions, and utility commands,
global management of the distributed store from any participating server,
networked access to the distributed store from remote client systems,
optional data replication and transparent access across multiple ScaleOut StateServer stores running in multiple data centers using the ScaleOut GeoServer option,
parallel query and parallel data analysis using an integrated computational engine (with the optional ScaleOut StateServer Pro),
a complete set of Windows Performance Counters for each ScaleOut StateServer host that report memory usage, access rates, and host status, and
sample code that shows how to make ScaleOut StateServer a second-level cache provider for NHibernate.
More about Workload Data
Relational DBMS’s have proven their value as the repository for essential line of business (LOB) data, such as inventory, purchase orders, billing records, etc. With the advent of “stateless” Web and application server farms, DBMS’s have increasingly been used to hold mission-critical but relatively short lived workload data, such as e-commerce shopping carts, SOAP requests, session-state, and intermediate business logic results. Workload data typically are updated several times prior to committing changes to the LOB database. The following table compares LOB data and workload data:
Characteristic |
LOB Data |
Workload Data |
|---|---|---|
Volume |
High |
Low |
Lifetime/turnover |
Long/slow |
Short/fast |
Access patterns |
Complex |
Simple |
Data preservation |
Critical |
Less critical |
Access update ratio |
~4:1 |
~1:1 |
Fast access & update |
Less important |
More important |
To maintain quality of service, workload data are often stored in a DBMS so that they can be preserved across outages of Web or application servers. This creates significant traffic to and from the data storage tier and delays responses to clients. It also consumes resources within the expensive DBMS while making only rudimentary use of its feature-rich capabilities. By storing workload data in ScaleOut StateServer, you can avoid the overhead and expense of using a DBMS server, while simultaneously improving response time, scalability, and availability. In effect, ScaleOut StateServer provides an additional, middleware-based storage tier that complements your existing storage tiers to maximize performance and cost-effectiveness.
Self-Discovery, Self-Aggregation, and Uniform Access
ScaleOut StateServer was designed to be as simple to install and use as possible. After you install ScaleOut StateServer on a server in your farm, you can create a store simply by activating the service. When you activate ScaleOut StateServer on additional servers in the farm on the network subnet, they automatically find the store that you originally created on other hosts (in a process called self-discovery), and then they joining the store (using self-aggregation) and take on a portion of its workload. Application programs can uniformly access and update any stored data object from any participating server in the store.
Scalability and Load-Balancing
ScaleOut Software StateServer delivers scalable throughput and fast response time by partitioning and dynamically load-balancing workload data across the servers within a farm. It works seamlessly with an IP load-balancer and enables every server to access any workload data object stored in the farm. ScaleOut StateServer’s distributed data store eliminates the bottleneck created by a centralized DBMS and provides fast response time by avoiding disk access and DBMS overhead. It also speeds up access by allowing simultaneous access to multiple data objects stored on different servers, and performance scales as the farm grows.
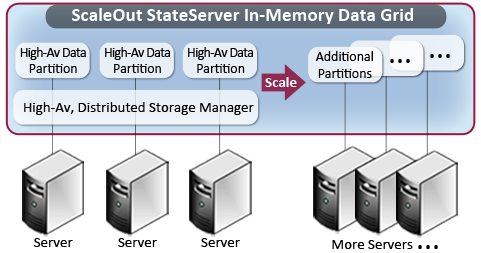
When a new server is added to the farm and joined to the distributed store, ScaleOut StateServer automatically integrates the server into the store and migrates a portion of the data (called a region) to it. This technique, called load balancing, controls the amount of data stored and managed by each server in the farm and ensures that each server handles an appropriate portion of the overall workload as determined by its memory capacity and CPU speed. You can specify the total amount of memory on each server to be used for storing data objects.
Data Replication, Self-Healing, and Recovery
ScaleOut StateServer uses patented technology to keep your workload data safe and highly available. It automatically and intelligently replicates data across up to two additional servers using a patented quorum-based updating algorithm which ensures that updates are reliably committed, even in the case of server or network failures. The following diagram illustrates the creation of two replica objects (shown in red) for each data object (shown in blue).

You can adjust the number of replica objects that ScaleOut StateServer creates for each stored object (1 or 2). Setting the number of replicas lets you make the appropriate tradeoff between high availability and memory usage.
This data replication technology automatically initiates recovery and self-healing after server failures. Recovery often requires less than ten seconds to failover and resume access to the affected data (versus one or more minutes for a clustered DBMS). After initial recovery, ScaleOut StateServer removes a failed or inaccessible server from the store and reconstructs data replicas on the remaining servers. This self-healing process (which may take a minute or more to complete) restores full data redundancy in case of a subsequent server failure.
ScaleOut StateServer maintains service to clients even after up to N-1 servers have failed in an N-server store (although data may be lost if all replicas of an object are lost due to failures). The service reports if it detects the possibility that data was lost due to a multi-server failure, and then it heals the store to maintain service to clients. Although data may be lost in various failure scenarios, ScaleOut StateServer maintains and/or restores service to client applications whenever possible.
Client Caching
ScaleOut StateServer incorporates a transparent, coherent, internal cache for deserialized data objects within its .NET, Java, and C++ client libraries. When objects are repeatedly read from the in-memory data grid, this cache reduces access response time by eliminating data motion and deserialization overhead for objects that have not been updated in the IMDG. Performance tests with the client-side cache show a dramatic reduction in average response time. Please see the section Performance Considerations for details.
Because ScaleOut StateServer’s server and client caches are automatically kept coherent with the in-memory data grid, they operate transparently to applications (i.e., applications do not have to keep track of whether to access a client-side cache versus the grid to obtain the most recently updated data). If an application updates an object in the grid, it can be sure that any subsequent access to that object will return the latest data. This simplifies the structure of applications while maintaining fast access times.
Transparent Support for ASP.NET in Windows
The Windows version of ScaleOut StateServer transparently stores ASP.NET session state, providing a seamless environment for your ASP.NET applications. Once installed, ScaleOut StateServer automatically saves ASP.NET session state objects in its distributed store and retrieves them when needed to complete a Web request. As your IP load balancer directs Web requests to different servers within a farm, ScaleOut StateServer keeps their associated session objects immediately accessible, regardless of the server that handles the request.
By default, ScaleOut StateServer separates the session objects created by different ASP.NET applications and makes them subject to memory reclamation when necessary. However, multiple Web applications optionally can share the same session objects instead of placing them into separate application name spaces. A configuration parameter within the ASP.NET web.config configuration file specifies the name space to be used for session objects and overrides ScaleOut StateServer’s default use of the Web application’s name for this purpose. In addition, automatic memory reclamation for ASP.NET session objects can be selectively disabled with a second web.config parameter.
API Support for .NET Languages, Java, C/C++, and HTTP REST Clients
You also can directly access ScaleOut StateServer’s in-memory data grid from .NET, Java, C/C++ applications using the application programming interfaces (APIs) supplied with the product. This gives you the flexibility you need to incorporate ScaleOut StateServer into your existing applications and delivers the best performance. The .NET APIs support all .NET languages, including C#, C++, and Visual Basic. Additional APIs support Java and standalone (“unmanaged code”) C/C++ applications, as well as any other applications with an HTTP client.
API Libraries
All ScaleOut client libraries are fully integrated with ScaleOut’s in-memory data grid (IMDG) and automatically keep track of the placement of objects within the grid. Their APIs give applications a simplified, location-transparent view of the IMDG and handle the details of sending requests to the optimal server, even in the case of membership changes and load-rebalancing.
The ScaleOut Product Suite provides four sets of client libraries:
the ScaleOut Client Library for .NET
the Named Cache APIs for .NET and Java
the Data Accessor (DA) APIs for .NET and Java
the Cached Data Accessor (CDA) APIs for .NET
The ScaleOut Client Library represents the next generation in .NET APIs for the ScaleOut Product Suite, offering full support for asynchronous APIs and compatibility with .NET Standard. As a planned replacement for the current Named Cache APIs, this library adds new flexibility for delevelopers and for configuring client applications. The library is available as a standalone NuGet package that has no dependency on ScaleOut’s installer. Configuration is performed through an app’s config file or application code, making it friendly to containerized/cloud applications. Full async support improves throughput in workloads that have a mix of heavy CPU and network I/O. In addition, core methods were renamed and redesigned to make functionality easier to discover, make code more explicit, and make it easier to build reliable distributed applications.
For Java developers, the ScaleOut Product Suiteprovides the Java Named Cache (JNC) APIs for Java, and Native Client APIs for C++.
The Named Cache APIs for both .NET and Java provide core APIs that application developers can use to access and analyze data stored in ScaleOut StateServer. These APIs have collection-oriented semantics for managing groups of logically related objects. They include full support for data-parallel computing with automatic code shipping to the IMDG. They also simplify the developer’s view of data shared across the IMDG. For example, they take care of polling for object locks, and they handle synchronization issues that occur when multiple hosts attempt to create an object with the same key. Since the Named Cache APIs contains features for data-parallel computing that are not yet available in the ScaleOut Library, it should be used for .NET applications that need to perform data analytics within the IMDG.
ScaleOut StateServer includes two additional sets of .NET APIs for lower level access to the in-memory data grid; they should rarely be used by application developers. The Data Accessor APIs provide low-level, direct access to the distributed store and manage state information for individual objects being accessed. The Cached Data Accessor APIs build upon the Data Accessor APIs to manage the complexities inherent in sharing, global, application-level data and thereby simplify application design.
ScaleOut StateServer also includes C and C++ APIs for use in C and C++ applications, and a REST API service for HTTP access. For more information on the APIs, please consult the associated documentation that is installed with the product or visit the documentation page on the ScaleOut Software web site.
API-Based Access
ScaleOut StateServer’s APIs provide simple, straightforward access to the distributed store so that you can:
store serialized data objects identified by a string or a 256-bit key and a namespace identified by a string or a 32-bit value,
read previously stored data objects,
update previously stored data objects, and
remove data objects from the store.
Data objects are stored as contiguous, opaque, binary data. All data objects are uniformly accessible from any server in the farm that runs ScaleOut StateServer and participates in the distributed store.
Objects are stored in user-defined namespaces, which are typically used to store logically related objects, such as shopping carts, stock prices, etc. The Named Cache APIs integrate the use of these namespaces into the concept of object collections in C#, Java, and C++; this makes object namespaces easy and intuitive to use. Many advanced features, including object locking, backing store integration, remote store access, and parallel query, can be managed on a per-namespace basis.
Objects optionally can be locked for up to ninety (90) seconds to synchronize distributed access from multiple threads running on different hosts. For example, a server can read and lock an object to maintain exclusive access until it subsequently updates and unlocks the object. Both pessimistic and optimistic locking models are supported.
To manage object lifetimes, objects can be assigned either a fixed (absolute) or a sliding timeout value from one (1) minute to forty-five (45) days after which the object is removed from the store. (ASP.NET session-state objects use the ASP.NET session timeout value.) An object’s sliding timeout is reset whenever the object is accessed. Objects can maintain dependency relationships to other objects so that they can be expired in logically related groups. ScaleOut StateServer also automatically reclaims memory used by the least recently accessed objects (which optionally can be marked as non-reclaimable) when a user-specified threshold is reached.
Windows Server AppFabric Caching Compatibility Library
ScaleOut StateServer includes the Windows Server AppFabric Caching Compatibility Library, which provide complete, source-level compatibility with the Windows AppFabric Caching APIs, including support for regions, tag-based query, and event notifications. In most cases, applications previously designed to use Windows AppFabric Caching as a distributed cache can easily migrate to ScaleOut StateServer with only a recompile. In addition, these applications can access ScaleOut StateServer’s extended functionality, such as fully distributed LINQ query, by calling native APIs side-by-side with AppFabric Caching APIs.
In addition to native management tools, ScaleOut StateServer provides PowerShell cmdlets that implement relevant AppFabric Caching management commands. Several management steps, such as creating of a configuration store and granting Windows account access to data caches, are not required by ScaleOut StateServer.
Scalable Event Handling
Applications can catch asynchronous session and timeout events so that session and application objects can be examined and explicitly re-saved or removed after a timeout occurs. For example, session data can be saved to a database server awaiting a future login to provide very long term storage for user sessions. ScaleOut StateServer takes full advantage of its built-in scalability and high availability to automatically distribute the event handling load across the server farm and to ensure that timeout events are delivered with high availability in case a server or network outage occurs.
ScaleOut StateServer extends its scalable event handling mechanism to remote clients by automatically distributing events across remote clients. In addition, it automatically handles the failure of remote clients by redirecting events to other remote clients if they are available. (This mechanism requires that there are at least as many remote clients as there are servers within the in-memory data grid.)
Parallel Query
Applications can quickly query the in-memory data grid to obtain a list of all objects that match a set of specified criteria. ScaleOut StateServer uses fully parallel lookup and internal indexing across all servers to deliver fast, scalable query performance.
Objects can be queried by class properties in .NET, Java, and C++ applications. (Stored objects also can be assigned explicit index values as metadata for querying by all applications.) C# applications can make use of .NET’s Language Integrated Query (LINQ) to structure queries using SQL-like semantics. Java and C++ applications can make use of “filter methods” to compose queries with logical and comparison operators. For high performance, ScaleOut StateServer’s client libraries automatically extract selected properties and store them as deserialized data during object updates.
Backing Store Integration
ScaleOut StateServer includes support for integrating the in-memory data grid with a backing store, such as a database server or file system. This feature is available in the Named Cache APIs for C#, Java, and C++. It incorporates a rich set of capabilities which let the user choose the appropriate policy for keeping the in-memory data grid in sync with a backing store to maximize application performance and minimize the load on the backing store. Two synchronous access policies (read-through and write-through) are settable for a named cache. Two asynchronous access policies (refresh-ahead and write-back) are settable for individual objects and run on a periodic basis using a specified timeout.
Remote Client Option
In some situations, it may be advantageous to run ScaleOut StateServer on a separate server farm that is networked to a Web or application server farm. This approach lets you provision the in-memory data grid (IMDG) with the dedicated CPU, memory, and networking resources required to handle the largest possible storage loads. It also offloads the IMDG’s use of these resources from your Web and application server farm.
To support this usage, the Remote Client option lets your application access a ScaleOut StateServer cluster from a networked computer. Once configured, the Remote Client option automatically connects to all of the servers in the cluster, and it load-balances its access requests to the servers within the store. The Remote Client option automatically handles membership changes in the IMDG by retrying access requests if a server fails and by tracking the addition of new servers to the IMDG.

Note
The ScaleOut Remote Client option is licensed separately from ScaleOut StateServer. Its functions are enabled by a license key from ScaleOut Software.
Note
The ScaleOut Remote Client Option is not used by Redis clients, which can connect directly to any host in a ScaleOut cluster by specifying the host’s IP address and server port within their configurations.
ScaleOut GeoServer® DR and Pro
An increasing number of companies employ multiple data centers to improve their quality of service and to help mitigate the impact of catastrophic events such as earthquakes and floods. If one data center goes offline, its workload can be handled by another, healthy data center to avoid service interruptions. For this strategy to be effective, changes to application data must be continuously replicated to a remote site so that it is quickly ready to handle the workload.
With version 3.0, the ScaleOut Product Suite introduced the ScaleOut GeoServer option and allowed distributed caching to extend across multiple, geographically distributed data centers. This option replicates stored objects between ScaleOut StateServer IMDGs running on server farms at different sites. The original GeoServer approach accomplishes replication by asynchronously pushing changes across WAN links as soon as objects are updated-a datacenter in New York City can continuously push its updates to Los Angeles, allowing the L.A. site to remain fully synchronized with NYC at every moment.
Version 5.0 of the ScaleOut Product Suite introduced a new, global access model that allows a remote site to pull objects from the local site as they are needed. Pull-based access allows objects to be shared by a geographically diverse network of in-memory data grids, with policies on each object dictating how frequently remote datacenters should update their copies of the object. Furthermore, the authoritative “primary” copy of an object can migrate from datacenter to datacenter as demand dictates.

Note
The ScaleOut GeoServer option is licensed separately from ScaleOut StateServer. Its functions are enabled by a license key from ScaleOut Software. Push-only replication can be licensed with the ScaleOut GeoServer DR option. Please contact ScaleOut Software sales for details.
Note
ScaleOut GeoServer does not support Redis databases in the current release.
“Push” Replication (ScaleOut GeoServer DR)
An increasing number of companies employ multiple data centers to improve their quality of service and to help mitigate the impact of catastrophic events such as earthquakes and floods. If one data center goes offline, its workload can be handled by another, healthy data center to avoid service interruptions. For this strategy to be effective, changes to application data must be continuously replicated to a remote site so that it is quickly ready to handle the workload.
The ScaleOut GeoServer option quickly and efficiently replicates cached data to a remote server farm for access after a site-wide failure. To start replication, you simply connect to a server on a remote farm using an existing virtual private network or other secure communications channel. ScaleOut GeoServer automatically configures itself to distribute traffic among servers within the remote server farm and then automatically forwards storage updates to the remote farm. To maximize performance and availability, all servers within both StateServer farms participate in data replication. As servers are added or removed at each farm, GeoServer automatically reconfigures its network connections to maintain the best possible replication performance without the need for manual intervention.
“Pull” Model (ScaleOut GeoServer Pro)
The ScaleOut GeoServer Pro pull model was introduced in version 5.0 of the ScaleOut Product Suite. Pull model differs from push replication in that objects are only transmitted across a WAN to remote datacenters as the objects are needed. Furthermore, the frequency that remote sites refresh their copies (called proxies) of an object can be adjusted by setting up a coherency policy that controls how out-of-date a replicated object may become before it is refreshed in a remote datacenter. A loose coherency policy can result in reduced bandwidth usage between sites when compared to push replication, since fewer updates are sent across the link between datacenters.
Updates performed on a remote, unlocked proxy of a replicated object will cause the updated value to be pushed across the WAN back to the datacenter containing the primary copy of the object.
Ownership of an object can migrate from datacenter to datacenter. The datacenter that contains the primary copy of an object will relinquish its ownership if an application in a remote datacenter acquires a lock on a proxy of the object (by either reading or locking the object). GeoServer’s pull replication architecture thereby extends ScaleOut StateServer’s distributed locking model to span datacenters, allowing a single thread on a single machine to acquire a lock so that no other client code across a globally distributed network of caches will be allowed to acquire a lock on that same object.
Because the ownership of an object can migrate from store to store, it is common for GeoServer pull replication to be configured in both directions (that is, Los Angeles would be configured to pull from New York, and New York would be configured to pull from Los Angeles). This allows the primary copy of an object to migrate from datacenter to datacenter as needed. GeoServer can also manage pull replication across more than two sites-for example, if three datacenters are involved, then each site will need to be separately configured to pull from the other two. If the remote sites will not be locking any replicated objects then configuring bi-directional replication is not necessary, since the primary copy of the object will always remain in the local site.
Note
Starting with version 5.10, the ScaleOut GeoServer Pro “pull” model provides optional, redundant data storage of objects between two data centers for disaster recovery combined with synchronized data access.
ScaleOut StateServer® Pro
The optional ScaleOut StateServer Pro integrates a powerful computational platform with ScaleOut StateServer’s in-memory data grid (IMDG). This enables applications to quickly and easily analyze data stored in the IMDG using a technology called “parallel data analysis.” It builds upon ScaleOut StateServer’s parallel query capability to analyze data with the grid servers instead of moving queried data back into a client system for lengthy, sequential analysis.
ScaleOut StateServer Pro adds a Parallel Method Invocation (PMI) API that lets developers quickly write data-parallel programs which operate on a queried set of objects stored within a single namespace. This powerful mechanism enables applications to obtain scalable performance by seamlessly distributing data-parallel tasks across both CPU cores and servers. With a single API call, an application can:
select a set of objects within a single namespace using a property-based query,
specify an “Eval” method that analyzes these objects and produces a result,
specify a second “Merge” method to combine the results and return a single combined result to the application.
Both methods directly access objects stored within the IMDG. By using PMI, applications can analyze objects within the IMDG and avoid the overhead of moving them into the client for processing. They also can offload the client and take advantage of the IMDG’s scalable computing power to quickly complete a data-parallel operation on a large number of objects.
Versions of this API are available for C#, Java, and C/C++.

In addition to PMI, ScaleOut StateServer Pro includes an API for .NET developers called Distributed ForEach, which is a distributed version of Microsoft’s popular Parallel.ForEach API. Like PMI, Distributed ForEach is integrated with LINQ query so that an application can select a set of objects to be processed by the data-parallel operation. This API conforms closely to the semantics of Parallel.ForEach with some modifications required to support distributed execution on a cluster of servers.
To simplify and automate the deployment of application code to grid servers for parallel method invocations, ScaleOut StateServer Pro enables C# and Java applications to define an invocation grid prior to running parallel method invocations on a collection of objects within a single namespace. The invocation grid specifies the application’s executable file and libraries which are needed to perform an invocation. When an invocation grid is loaded, ScaleOut StateServer Pro creates a set of worker processes, one per grid server, and loads the application’s executable file and libraries in preparation for running parallel method invocations. Once a named cache is associated with an invocation grid, all parallel method invocations on this named cache automatically are sent to the invocation grid’s worker processes for execution.
ScaleOut StateServer Pro also includes an API called “single method invocation” (SMI) which lets C# and Java applications invoke a method on a specified object, supply parameters to invocation, and receive the method’s result value. Because of its highly optimized implementation which avoids all unnecessary network copies, SMI can be used to efficiently analyze a targeted set of stored objects as an alternative to Parallel Method Invocation (PMI). In addition, applications can use SMI to efficiently update stored objects without replacing their full contents in a manner similar to the use of stored procedures in database systems.
Note
ScaleOut StateServer Pro is licensed separately from ScaleOut StateServer. Its features are enabled by a license key from ScaleOut Software and include all of the features of ScaleOut StateServer.
ScaleOut StreamServer®
ScaleOut StreamServer combines a scalable, stream-processing compute engine with an integrated, in-memory data grid (IMDG) into a powerful, unified software platform for stateful stream processing. Applications can perform lightning-fast event analysis using sophisticated in-memory state tracking to provide deep introspection and precise real-time feedback. Ideal for a wide range of applications, including the Internet of Things (IoT), manufacturing, logistics, and financial services. ScaleOut StreamServer introduces breakthrough technology for the next generation in stream processing.
Live systems generate streams of incoming events that need to be tracked, correlated, and analyzed to identify patterns and trends and then generate immediate feedback and alerts to steer operations. With today’s ever more complex real-time systems, it’s not enough to just analyze patterns within data streams using conventional techniques. Applications need deeper introspection to extract full value from the telemetry they receive. They need to build dynamic models of data sources that they can continuously update and analyze. Called stateful stream processing and popularized as the digital twin by Gartner, this breakthrough approach can harness machine learning, neural networks, and other advanced techniques to enable deep introspection and provide precise, timely feedback for live systems.
ScaleOut StreamServer’s innovative architecture delivers both breakthrough capabilities and peak performance for stateful stream processing. It processes incoming data streams within an in-memory data grid - where the data lives - ensuring minimum latency and peak throughput. Other platforms need to pull state information from remote data stores, such as database servers and distributed caches; this creates delays and network bottlenecks. Instead, ScaleOut StreamServer delivers streamed events directly to their associated state data, enabling immediate, fully contextual processing. Its transparently scalable platform minimizes the latency required for event tracking and analysis, ensuring timely feedback and/or alerts for the largest workloads.
ScaleOut StreamServer’s capabilities are delivered as an intuitive, easy to use SDK that makes application development in C# and Java simple and straightforward. Key features and capabilities include:
All of the features in ScaleOut StateServer and ScaleOut StateServer Pro
Integrated IMDG and stream-processing engine to enable digital twin models while avoiding unnecessary data motion
Automatic code shipping to grid servers to simplify application deployment
Support for Reactive Extensions APIs for fast, straightforward event processing using familiar APIs
Integration with Kafka connectors and producers to enable seamless connectivity to Kafka messaging pipelines
Transparently scalable Kafka connections that maximize messaging throughput as the workload grows
Comprehensive time windowing libraries that make it easy to add time windowing to digital twin models
Automatic event routing to associated grid objects that scales throughput as grid servers are added
Note
ScaleOut StreamServer is licensed separately from ScaleOut StateServer. Its functions are enabled by a license key from ScaleOut Software.
ScaleOut hServer®
ScaleOut hServer enables standard Hadoop MapReduce programs to access data directly from ScaleOut StateServer’s IMDG and provides a full execution engine that enables standard Hadoop MapReduce programs to execute entirely within ScaleOut hServer’s infrastructure. ScaleOut hServer runs in both Linux and Windows environments and is certified for use with both Cloudera 5 and Hortonworks 2.1.
In addition to supporting Hadoop MadReduce, applications can easily create, read, update and delete fast-changing data in the ScaleOut IMDG using straightforward Java APIs. Together, these capabilities enable you to bring the power of Hadoop’s analytics to live, operational systems.
Applications also can use ScaleOut hServer as an in-memory data cache for HDFS data sets which fit within the IMDG’s memory. In this usage model, when you run a Hadoop MapReduce, key/value pairs pass from your HDFS record readers into the mappers, and ScaleOut hServer stores them in the IMDG. On subsequent runs, it transparently reads key/value pairs from the IMDG, providing a significant speed-up in data access time.
ScaleOut hServer’s new Java API library integrates Hadoop MapReduce with ScaleOut StateServer’s in-memory data grid (IMDG). This open source library (licensed under the Apache License, Version 2.0) consists of several components: a Hadoop MapReduce execution engine, which runs MapReduce jobs in memory without using Hadoop job trackers or task trackers, and four I/O components to pass data between the IMDG and MapReduce job. The I/O components include the Named Map Input Format, the Named Cache Input Format, and the Grid Output Format that together allow MapReduce applications to use the IMDG as a data source and/or result storage for MapReduce jobs. In addition, the Dataset Input Format accelerates the performance of MapReduce jobs by caching HDFS datasets in the IMDG.
Using ScaleOut hServer, developers can write and run standard Hadoop MapReduce applications in Java, and these applications can be executed stand-alone by ScaleOut hServer’s execution engine. The Apache Hadoop distribution does not need to be installed to run MapReduce programs; it is only needed to optionally make use of other Hadoop components, such as the Hadoop Distributed File System (HDFS). (If HDFS is used to store data sets analyzed by MapReduce, ScaleOut hServer should be installed on the same cluster of servers to minimize network overhead.) ScaleOut hServer’s execution engine offers very fast job scheduling (measured in milliseconds), highly optimized data combining and shuffling, in-memory storage of intermediate key/value pairs within the IMDG, optional use of sorting, and fast, pipelined access to in-memory data within the IMDG for analysis. In addition, ScaleOut hServer automatically sets the number of splits and partitions for IMDG-based data. Lastly, the performance of the Hadoop MapReduce engine automatically scales as servers are added to the cluster and IMDG-based data is automatically redistributed across the cluster.
Developers can use ScaleOut hServer’s Java APIs to create, read, update, and delete objects within the IMDG. This enables MapReduce applications to input “live” data sets which are stored and updated within the IMDG. Complex IMDG-based objects can be stored within a named cache, which provides comprehensive semantics, such as object timeouts, dependency relationships, pessimistic locking, and access by remote IMDGs. These objects are input to MapReduce applications using the Named Cache input format. Alternatively, large populations of small key/value pairs can be efficiently stored within a named map, which provides highly efficient memory usage and streamlined semantics following the Java concurrent map model. These objects can be input to MapReduce applications using the Named Map input format. The Grid output format can be used to output objects from MapReduce applications to both a named cache or a named map.
ScaleOut hServer is available as a free community edition for use on up to 4 servers or 256GB of data, or for unrestricted use with a commercial edition.
Management Tools
You can manage ScaleOut In-Memory Database and ScaleOut StateServer using these management tools:
the StateServer Management Console,
the StateServer Web Management Console,
the soss Command command-line control program, and
the geos Command command line control program for the GeoServer option.
The Windows and web-based management consoles offer a centralized, graphical user interface that gives you the status and performance of ScaleOut StateServer’s distributed store (including ScaleOut In-Memory Database’s Redis database) and of its participating servers, called hosts. You also can configure and control individual hosts from the console, which runs on any server in the farm that runs ScaleOut StateServer. You can join all hosts to the distributed store or have all hosts leave the store with one command. In addition, you can simultaneously restart the StateServer service on all hosts to form a new distributed store. Using the Remote Client option, you can manage a remote IMDG from a networked administrative workstation. The management console includes real-time performance charting and a “heat map” that shows activity and health of the in-memory data grid.
Note
Linux systems can be managed from a remote Windows system using the Windows Management Console, which is available in the Windows installation package.
The soss Command command-line program provides all of the capabilities of the management console with individual commands that you can run from a command prompt. You can use the soss command to quickly obtain status information, make configuration changes, control hosts, or wait to be notified of a status change. You also can use this tool to incorporate control of ScaleOut StateServer into your command-line scripts.
The geos Command command line program adds support for the GeoServer option. When used in conjunction with the soss Command command-line program, it provides all of the capabilities of the management console.
Optional ScaleOut Management Pack
The ScaleOut Management Pack adds important enhancements to ScaleOut StateServer’s built-in management tools for managing, analyzing, and protecting data stored in ScaleOut StateServer’s distributed grid. The Management Pack licenses the use of three components: an object browser for visually browsing and managing objects stored in the in-memory data grid, a parallel backup and restore feature for archiving its contents in the file system, and the Management REST Service.
Object Browser
The ScaleOut Object Browser lets you directly browse data stored within the in-memory data grid. This gives developers and administrators a unique new means of accessing the contents of the data grid, including both metadata and serialized data for individual C/C++, Java, and .NET objects. In addition, the object browser can load .NET assemblies so that it can deserialize .NET objects and display properties/fields from custom classes, including items within ASP.NET session objects.
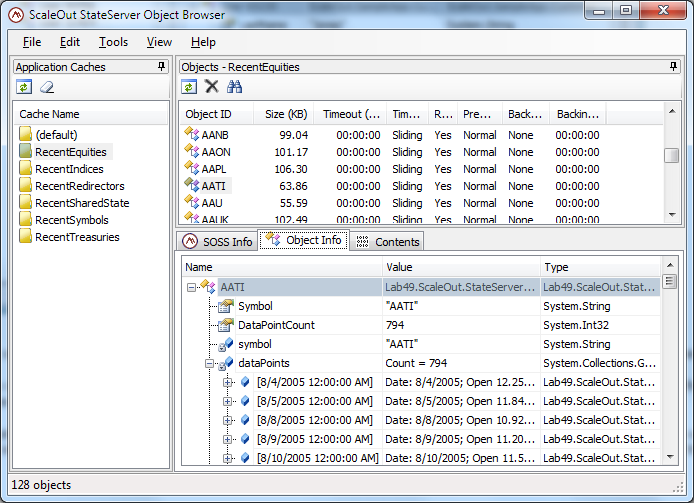
The object browser can also help you manage stored data. For example, you can browse the data grid to find specific objects by name or find all objects in a particular named cache within the grid that may be of interest. Objects can be sorted by name, size, or other attributes. The object browser also lets you clear individual objects, groups of objects, or the entire data grid.
Note
In the current release, the ScaleOut Object Browser is not able to display objects stored in the Redis database.
Parallel Backup/Restore
The ScaleOut Parallel Backup and Restore Utility saves and restores all of the data within the data grid or a selected named cache to and from the file system. It also can backup and restore all objects in the Redis database.
Note
ScaleOut’s backup simultaneously operates on all servers in the cluster (unlike the Redis SAVE command, which operates on a single server). Likewise, backup files are applied to all servers. A restore operation can be applied to a different server configuration than was used for backup. For example, a backup from a 3-server cluster can be restored to a 2-server cluster.
Backup/restore operations are allowed while the grid is active. This utility delivers extremely high performance, and its unique, fully parallel architecture ensures that backup/restore operations never become a bottleneck as the grid grows to handle large volumes of data. For maximum speed and scalability, backup/restore operations are performed in parallel on all grid servers.
Beyond archiving grid data for disaster recovery, the ability to perform backups while the data grid is active has many additional uses. For example, snapshots of the grid’s data can be captured at key times and saved for later analysis, and multiple snapshots can be taken over time to analyze trends.
Backup/restore operations are initiated and controlled from the Windows (or web-based) ScaleOut Management Console application. The console also reports on the status of an ongoing operation and automatically coordinates requests from multiple consoles. ScaleOut StateServer’s command-line management program also can be used to manage backup and restore requests.
By default, backups are targeted to a unique, time-stamped set of files within ScaleOut StateServer’s backup directory on each grid server. You can also specify a path name to a file share accessible by all grid servers, and all backup files automatically will be merged into that directory instead. For maximum flexibility in managing backed up data, you can collect the backup files created in parallel on the grid servers and then restore them from a single file share.
Together, the Management Pack’s capabilities dramatically increase both the grid’s visibility and manageability. Your data grid applications can benefit in numerous ways. For example, ecommerce applications can use the object browser to inspect customer shopping carts in real-time, tracking sales and managing inventory to optimize supply chain management. Likewise, financial applications can use the backup and restore utility to quickly and repeatedly take snapshots of data for later analysis of market trends, which is particularly useful for portfolio risk analysis and algorithmic trading scenarios.
Note
The ScaleOut Management Pack is licensed separately from ScaleOut StateServer. Its functions are enabled by a license key from ScaleOut Software that includes support for this option.
Management REST Service
The Management REST Service defines a set of REST endpoints that can be used to retrieve information about the state of a ScaleOut StateServer IMDG. It runs as a Windows service or Linux daemon on all ScaleOut StateServer hosts and hosts enpoints to retrieve detailed status information about the IMDG, hosts, clients, namespaces, remote stores, and backup operations. Please see the section Management REST Service for details.